重点关注的
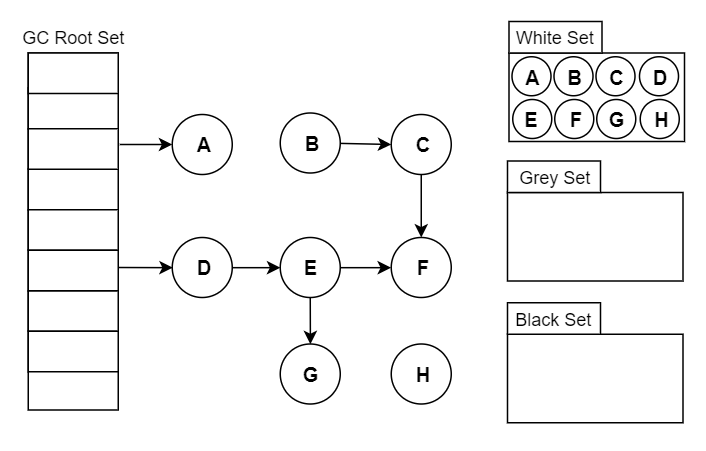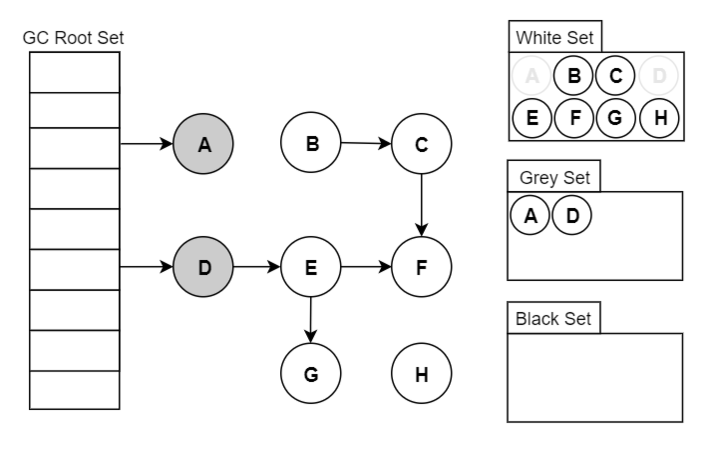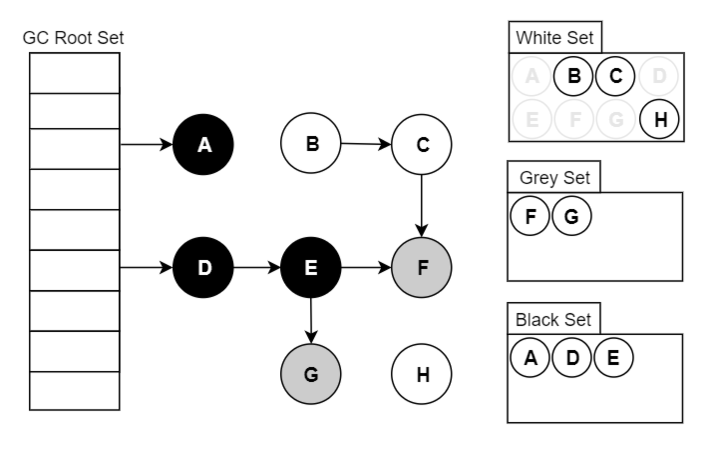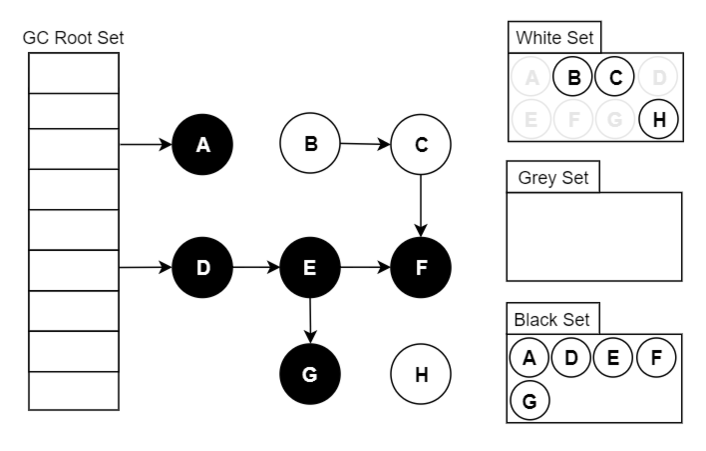
可达性分析原理:三色标记
原子性、有序性、可见性、as-if-serial、happen-before、sync、volatile的关系
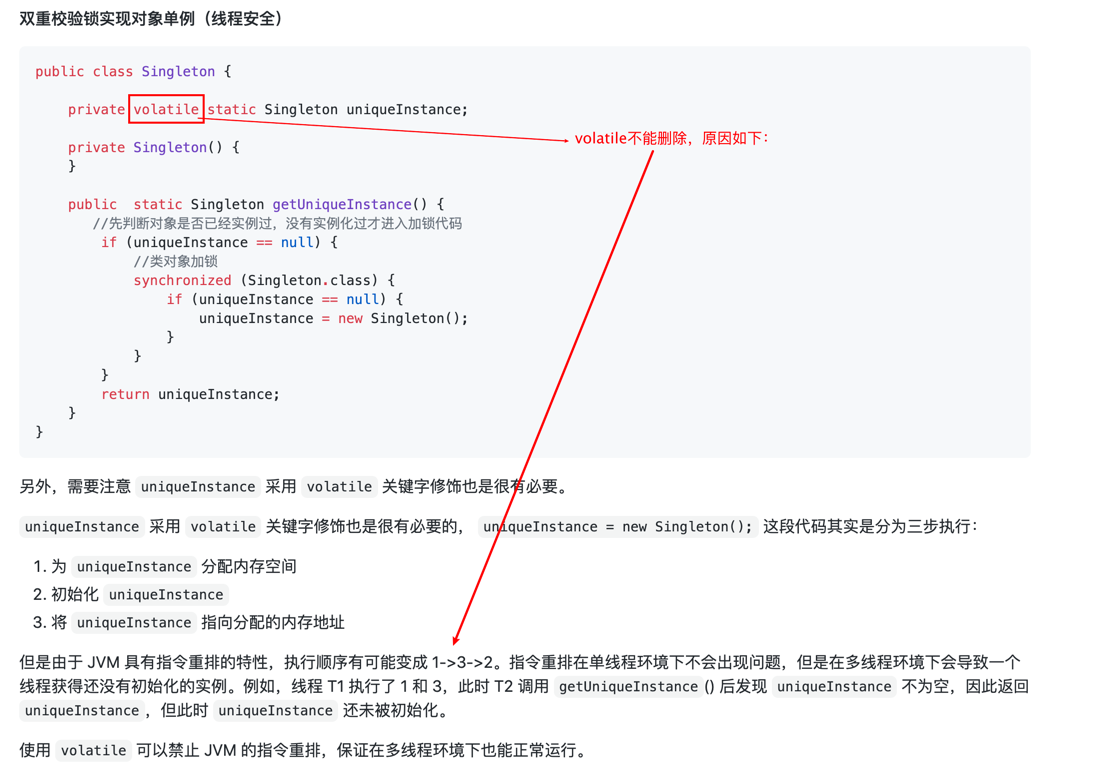
sync与volatile的区别
- sync可以保证原子、有序、可见性但不能阻止指令重排,volatile可以保证可见,也能阻止指令重排
ConcurrentHashMap
ConcurrentHashMap 和 Hashtable 的区别
Java集合框架常见面试题
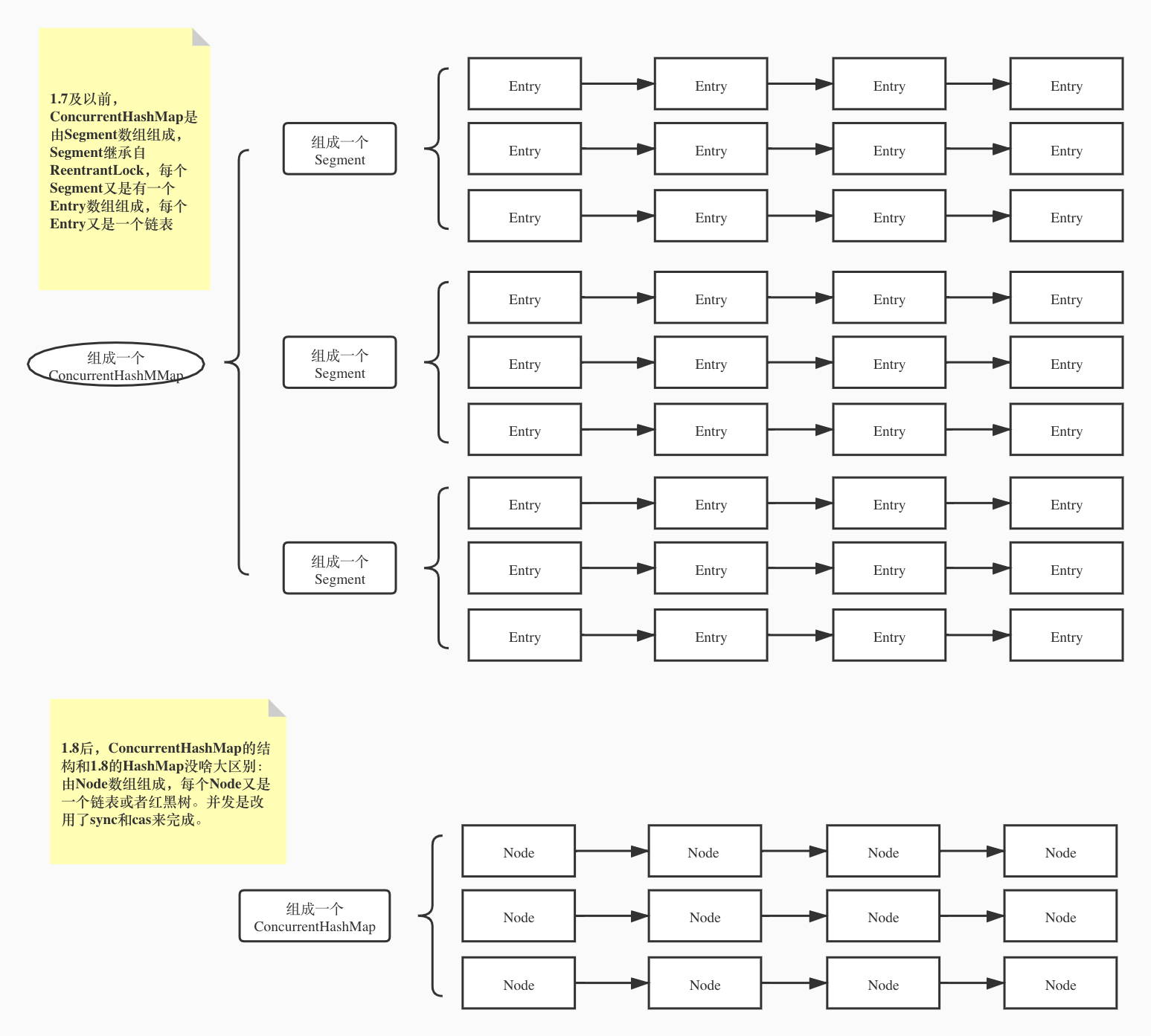
JDK1.8中的ConcurrentHashMap的死循环
为啥1.8的ConcurrentHashMap需要通过sync和cas来实现同步而不直接采用cas呢?
因为如果某个桶是红黑树的结构,这个时候可能需要对整棵树进行调整,所以它锁的是桶的首节点。ConcurrentLinkedQueue就只是通过cas来完成的
HashMap的resize细节
Explain
ES打分相关性
a b c建立联合索引顺序是abc,问a=? and c = ? 可以走索引吗?
可以的,但是走索引的时候的比对条件是a,先找到满足a条件后通过using where过滤掉不满足c的数据。
BASE理论
CAP理论
JVM调优
- 阿里巴巴数据库连接池的fullgc
- 显示CPU 100%
- 大概场景是一个同事写了一个循环函数,跳出循环的代码逻辑有点问题,导致无法退出循环,最终导致cpu 100%。
- 具体场景出来:
- top -Hp pid 找到cpu最高的线程id,是线程id;
- printf '%x' 线程id,得到线程id的16进制
- jstack pid | grep -A 20 线程id的16进制,找到线程执行的具体代码,检查代码
- jvm内存大小的调优
- GC调优:垃圾收集器的调优
知识列表
String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?
String为啥要设计为不可变

接口和抽象类的区别是什么?
== 与 equals(重要)
hashCode 与 equals (重要)
简述线程、程序、进程的基本概念。以及他们之间关系是什么?
线程有哪些基本状态?
Java序列化中如果有些字段不想进行序列化,怎么办?
Java 中 IO 流
深拷贝 vs 浅拷贝
BigDecimal 的用处
BigDecimal 的使用注意事项
Arrays.asList注意事项
get和post请求的区别
转发(Forward)和重定向(Redirect)的区别
Cookie和Session的的区别
说说List,Set,Map三者的区别?
说一说 ArrayList 的扩容机制吧
HashMap的底层实现
HashMap 多线程操作导致rehash方法死循环问题,jdk1.8之前
集合框架底层数据结构总结
什么是线程和进程?
说说 sleep() 方法和 wait() 方法区别和共同点?
谈谈你对sync的理解
谈谈 synchronized和ReentrantLock 的区别
两者都是可重入的
sync是基于jvm实现的,是隐式锁,而ReentrantLock是基于java api实现的,是显式锁。
性能方便sync做了很多优化措施,差不多
ReentrantLock 比 synchronized 更加灵活(主要是Lock接口里的几个方法展开说就可以了)
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}
volatile关键字
ThreadLocal
- 一句话总结:让线程可以绑定只有自己才能访问的数据
一篇文章彻底了解ThreadPoolExecutor
JUC 包中的原子类是哪4类?
也许是把AQS讲得最通俗易懂的一篇文章
AQS 组件总结
CopyOnWriteArrayList
并发容器总结
跳表
每个栈帧中都拥有:局部变量表、操作数栈、动态链接、方法出口信息
类加载器
计算机网络常见面试题
不了解布隆过滤器?一文给你整的明明白白!
为啥选用RocketMQ不用RabbitMQ
吞吐量比RabbitMQ高(Kafka: 16-17w;RocketMQ:11-12w;RabbitMQ: 2-3W)
支持顺序消息
JAVA语言开发,经受住双十一的考验的
支持分布式部署,在可用性方便比RabbitMQ高。RabbitMQ是主从架构
信息丢失方面可以通过0丢失(设置同步刷盘也能不丢失)
RocketMQ是如何保证高可用的?
从部署架构上说,可以部署多个brocker,把同一个topic的中队列分布在多个brocker上,这样可以减轻某个单台brocker的压力。同时多个brocker还可以各自做一个主从结构,这样如果某个brocker master挂了,其对应的slave也可以顶上来。
然后除了brocker可以做集群,还可以nameserver也可以做集群。namaserver集群中各个nameserver是互相独立的,每个brocker会和每个namaserver保持连接,并定期发送心跳、topic等路由信息。另外生产者和消费者也会定期从nameserver中拉去brocker的路由信息。这样,即便某个nameserver挂了,其他的nameserver也能顶上来。在坏一点,如果所有nameserver都挂了,那么生产者和消息者还可以利用本地保留的路由副本和brocker保持通信。
上面是从部署架构上说,从单台brocker方面而言,其刷盘的方式也可供我们选择。如果选择同步刷盘,还可以保证消息不会丢失。
另外brocker的主从结构也提供了同步复制和异步复制两种方式可供选择,这从一定程度上也保证了可用性
kafka如何保证消息不丢失
RockerMQ为啥采用nameserver作为注册中心而不是zk
RocketMQ的存储机制
把所有接受到的消息 (不区分topic) 都顺序的存在一个称为commitlog的文件中(物理不是一个文件). 为啥不分topic: 为了批量顺序写消息,提高写入速度
consumequeue文件中的目录采用定长设计(8字节物理偏移量,4字节消息大小,8字节tag的hashcode)。这里的物理偏移量不是相对于某个具体commitlog文件,而是性对于整个commitlog文件(就是把所有单个commitlog合在一起看)
consumerqueue的存在路径是:$HOME/store/consumequeue/{topic}/{queueId}/{fileName},也就是说当某个消息来了,rocketmq会先追加到commitlog中,然后根据这条消息要发往的topic和queueid信息再把这小消息的索引信息写到对应的consumequeue中
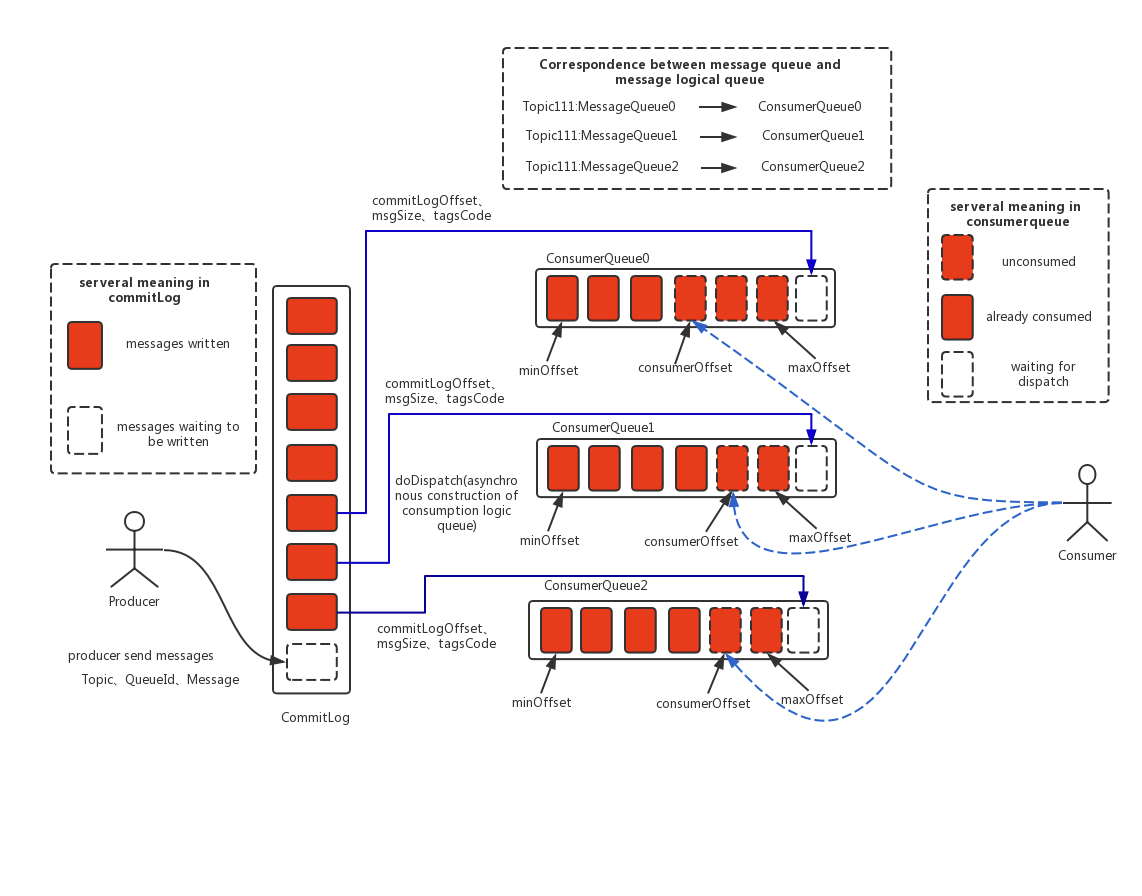
Kafka的存储结构


所以当要读取第n个消息的时候,只需要对index或者log文件的文件名进行二分查找,这样可以确定在哪个log文件中,然后在对应的index文件中在进行一次二分查找,就可以确定这条消息在log文件中的物理偏移量了
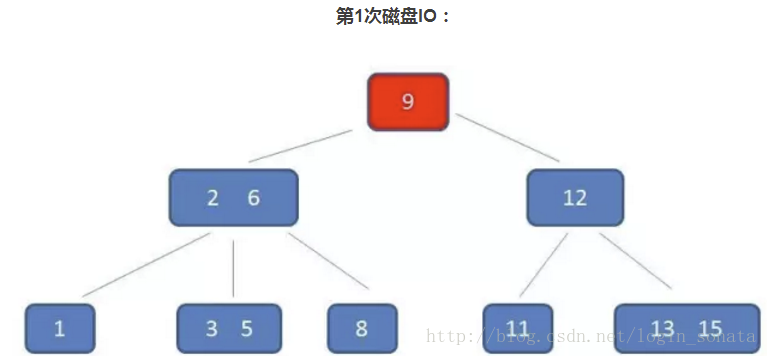
B数和B+数的区别
B数
关键字集合分布在整颗树中;
任何一个关键字出现且只出现在一个结点中;
搜索有可能在非叶子结点结束;
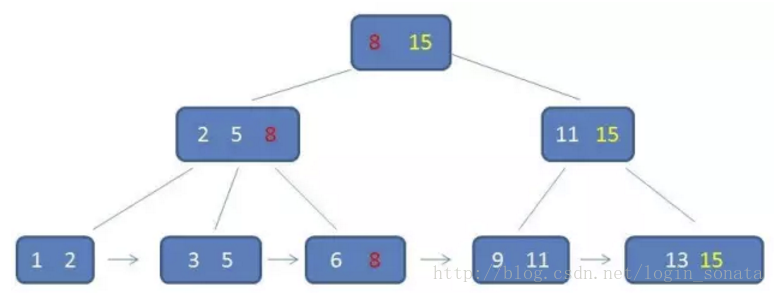
enter description here b+树相比于b树的查询优势:
b+树的中间节点不保存数据,所以磁盘页能容纳更多节点元素,更“矮胖”;
b+树查询必须查找到叶子节点,b树只要匹配到即可不用管元素位置,因此b+树查找更稳定(并不慢);
对于范围查找来说,b+树只需遍历叶子节点链表即可,b树却需要重复地中序遍历,如下两图:
Java栈数据结构
限流算法
熔断器
https的原理
Spring Boot自动装配的原理
- SpringApplicationn.run(XXXX.class)
- 读到XXXX.class上SpringBootApplication注解
- 读到SpringBootApplication类上的EnableAutoConfiguration注解
- 读到EnableAutoConfiguration类上的Import注解,和AutoConfigurationImportSelector类
- AutoConfigurationImportSelector的有个方法会扫描类路径下的所有META-INF/spring.factories文件
- 这个文件里可以配置多个第三方类,通过这种方式类触发第三方框架集成到Spring中,包括读取自己的配置文件
系统推荐
- RSA 加密解密多语言实现方案
- 在没有 telnet 和 nc 的世界里,如何优雅地判断端口是否通?
- IO相关
- 制作KVM ES镜像文件
- AQS源码解读
- JetBrains-License-Server
- 前端axios下载csv文件乱码
- Docker跨主机通信方案
- CentOS7下Docker端口映射后防火墙失效
- 免费 API 每日提供摸鱼日报,自动返回无水印图片,适用于公众号和小程序
- 杂记
- 表单重复提交解决方案
- 随机毒鸡汤:双十一过后,我从一个光棍,变成了一个负债累累的光棍。
