整体思路
- 使用已有的elk docker镜像sebp/elk快速搭建elk平台
- sebp/elk镜像中包括了elk三个服务。
- 在日志所在机子使用filebeat把日志传输给elk的logstash(logstash处理日志后把日志传输给es,然后kibana基于es分析数据)
关键问题
为了充分利用kibana的功能 ,要求存储在es中的数据需要json化。 那么问题来了,日志流入es的过程是:公司系统--->日志文件--->filebeat--->logstash--->es。
公司采用的日志系统是java的logback ,pattern定义如下:
%date %level [%thread] %logger{10} [%file:%line] %msg%n%n
之所以后面两个换行,本意是想通过空白行来区分哪些日志是属于同一个日志事件
问题如下
- 这个pattern表面上是有格式的,但不属于json格式。
- %msg输出的内容格式不可控,虽然公司有些日志是统一打印的,这部分拥有固定的一个格式,但还是存在部分格式不可控的日志。
- 异常堆栈信息默认情况下不会包含在%msg中,于是类似:log.error("业务异常",exception) 这样的语句,打印出来的日志会是这样的:
%date %level [%thread] %logger{10} [%file:%line] %msg
java的异常堆栈信息:
at .....
at .....
at ....
注意上面存在一个空白行,于是我们想要通过空白行来区分同一个日志事件的想法泡汤了。
日志json化解决思路
根据日志的流入过程:公司系统--->日志文件--->filebeat--->logstash--->es。
我们可以在上面的任何一个环节或多个环节做文章来达到流入es的日志的json格式的目的。
方案一:配置filebeat和logstash
不更改公司系统代码,保留原来的日志格式。在filebeat和logstash中做处理,来解决多行日志属于一个日志事件和json化的问题。
这个方案优缺点很明显: 优点:不用更改现有的代码 缺点:需要研究如何通过filebeat或者logstash来准确的区分哪些日志行是属于同一个日志的问题。区分出同一个日志事件的日志内容后,需要研究如何把日志json化。
我刚开始就是采用的这个方案,研究后得知
- 通过配置filebeat的multiline配置,可以把多行日志纳入到一个日志事件。
- 通过配置logstash的filter中的grok表达式,可以把日志内容json化。
于是去研究multiline如何配置,然后做实验,发现这个配置比较难理解。然后本身日志存在这样的问题:如果打印日志的时候,没有打印堆栈,则可以通过空白行来分区同一个日志内容。如果打印日志的时候打印了错误堆栈,则同一个日志事件中还会存在一个空白行。(原因在上面分析过了)还要命的是如果先后执行这样的日志打印语句:
log.error("error",exception);
log.info("info");
log.error("error2");
那么打印出来的日志会是这样的:
error
excepiton:xxxx
at ......
at .....
at .......
at ......
info
error2
可以看出,如果以空白行区分,不但会把原本属于同一个日志事件的日志分开,还会把不属于同一个日志事件的日志误认为属于同一个日志事件。
当然这个问题也可以解决,后来折腾半天发现为啥子要以空白行分割嘛,直接把分区日志事件的逻辑改为:已日期开头的日志属于新的一个日志,就完美解决这个问题了。(给自己有个白眼🙄)
这样更改后,通过filebeat的multiline解决了日志分割的问题。 下面需要解决日志json化的问题:关键点:grok表达式。 这个表达式的学习完全没有必要从头开始学或者系统的学习,我完全是依葫芦画瓢学习的。这里举一个非常简单的例子体验一下: 网址:http://grokdebug.herokuapp.com/ 或者 http://grok.elasticsearch.cn/ 在input输入:
2018-12-21 16:00:54,774 INFO c.l.c.w.l.AccessLog [AuthAndAccessLogAop.java:191] {"request":{"headers":{"Accept":"*/*","Connection":"close","User-Agent":"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)","Accept-Language":"zh-cn"},"params":{},"uri":"/api/test/echo","method":"GET","time":"2018-12-21 16:00:54"},"response":{"msg":"success","data":[1,2,3]},"checkTokenTime":0,"controllerTime":2}
在pattern中输入:
((?<datetime>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2},\d{3}) (?<level>.{3,5}) (?<logger>.*) \[(?<file>.*\.java):(?<linenum>.*)\] )
然后会输出:
{
"datetime": [
[
"2018-12-21 16:00:54,774"
]
],
"level": [
[
"INFO"
]
],
"logger": [
[
"c.l.c.w.l.AccessLog"
]
],
"file": [
[
"AuthAndAccessLogAop.java"
]
],
"linenum": [
[
"191"
]
]
}
通过这个例子,大家应该可以很快根据输入写出自己的grok表达式。
问你题来了: 如果输入是有固定的格式,那么很容易通过grok表达式把日志json化,但是现在的情况是日志格式不统一 (哭~~~)。
当然可以通过想办法把日志按照格式分类,或者统一日志格式,然后处理。但是这个办法需要需要在日志源头处改动,不满足本方案的要求。
于是鉴于公司的情况,本方案我折腾了大半天宣告失败。
方案二:从日志源头处改动
既然选择从日志源头处改动了,那么索性直接在源头处将日志json化。不要再filebeat和logstash处做过多额外的配置。要不然绑定的太多因素,不方便控制。 这个方案的优缺点也很明显: 缺点: 1. 需要改动原系统的代码或者配置。 2. 改动后的日志阅读习惯会发送小心的改变,应为json化了嘛。 3. 已经生成的日志照顾不了 优点: 1. 改动灵活,想怎么改就怎么改, 2. 不需要额外学习filebeat和logstash的太多配置。比如multiline和grok表达式。
问题也来了:如何把java日志json化?
这里直接给出我的解决方案,在这套方案前,尝试过好多种方法,最终这个方案最满意,改动也小,甚至不需要改动原来的代码,只需要对logback的配置做更改。
原来logback的patternn:
%date %level [%thread] %logger{10} [%file:%line] %msg%n%n
现在logback的pattern:
{ "date":"%date", "level":"%level", "logger":"%logger{10}", "file_line":"%file:%line", "msg":%msgext, "exception":%ex }%n%n
其实改动很小是不是😂,的确改动很小。之前在上家公司的时候,一个运维的同事问我可不可以打印json格式的日志,我当时想了想回答:这个怎么打呀?估计不行,比如那个异常堆栈,这个怎么搞?
现在想想,就这么简单,当时咋没想到改动pattern呀😂。
但是问题还是来了:新的pattern里有两个新的东西:%msgext 和 %ex
大概能猜到分别干嘛的: %msgext :替换了原来的 %msg ,用来处理我们打印的内容(非异常信息) %ex : 用来处理异常堆栈信息
这两个东西在哪里告诉logback呢,这这里:
<configuration>
<conversionRule conversionWord="ex" converterClass="com.xxxx.StackTraceConverter" />
<conversionRule conversionWord="msgext" converterClass="com.xxxx.MsgConverter" />
</configuration>
只需要在logback配置文件的configuration节点中加上这两个配置就可以了。 这是两个java类,代码如下:
public class StackTraceConverter extends ThrowableProxyConverter {
public StackTraceConverter() {
}
@Override
public String convert(ILoggingEvent event) {
//拿到异常信息
IThrowableProxy tp = event.getThrowableProxy();
//如果没有异信息
if (tp == null) {
//返回字符串 : "\"\""
return JsonUtils.serialize("");
}
//如果有异常信息
String ex = super.convert(event);
//json化
return JsonUtils.serialize(ex);
}
}
public class MsgConverter extends ClassicConverter {
public MsgConverter() {
}
@Override
public String convert(ILoggingEvent event) {
String msg = event.getFormattedMessage();
try {
JsonUtils.deserialize(msg, Map.class);
return msg;
} catch (Exception e) {
Map<String,String> map = new HashMap<>(1);
map.put("value",msg);
return JsonUtils.serialize(map);
}
}
}
上面用到的JsonUtils是我们自己封装了下json工具,可以替换为任何json工具类。
这样一做了调整后,打印出来的日志就是json了。有几个注意的地方:扩展的这两个convert最好都返回json格式的数据,至于为什么我也讲不明白,只是经验而谈。也许有些问题我遇到了其他人未必会遇到😜。
从源头上对日志进行了json化后,还有一个问题了:filebeat拿到一行日志后,给logstash,如果不做处理,logstash只会把这行日志当作普通文本,并不会当作json处理呀~
于是搜索: logstash 解析 json 数据。很快速得知答案:在filter里做如下配置:
filter {
json {
source => "message"
#target => "doc"
# message字段保留的就是整个json数据,如果把下面的语句生效,则流入es的数据中,没有message这个字段。具体效果可以自行做实验
#remove_field => ["message"]
}
# 这里是在处理日期时间,因为日志本身有时间,然后logstash会自行生成一个时间字段:@timestamp ,显然应该以日志里的时间为准。所以有如下配置:替换@timestamp字段的值为日志本身的时间。
date {
match => ["date","yyyy-MM-dd HH:mm:ss,SSS"]
target => "@timestamp"
locale => "cn"
timezone => "Asia/Chongqing"
}
}
到此,方案二结束。接下来我们来安装elk实施日志分析。
在centos7上安装docker
可参照官网安装步骤:https://docs.docker.com/install/linux/docker-ce/centos/
也可执行以下步骤:
移除旧版本:
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-engine
安装必要的工具:
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
添加软件源:
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
更新 yum 缓存:
sudo yum makecache fast
安装 Docker-ce:
sudo yum -y install docker-ce
国内配置镜像:
vim /etc/docker/daemon.json (这个文件也许不存在,新建一个即可)
把下面的镜像复制到daemon.json文件中
{
"registry-mirrors": ["http://hub-mirror.c.163.com"]
}
启动 Docker 后台服务:
sudo systemctl start docker
测试运行 hello-world:
docker run hello-world
如果出现类似下面的提示,恭喜你安装成功 
安装elk
拉取镜像
docker pull sebp/elk
创建es数据存放目录:
mkdir -p /var/data/elk
已sebp/elk镜像启动容器,并命名为:myelk
docker run -d -p 5044:5044 -p 5601:5601 -p 9200:9200 -p 9300:9300 -v /var/data/elk:/var/lib/elasticsearch --name=myelk sebp/elk
myelk中会启动三个服务:
- logstash,占用5044端口
- kibana,占用5601端口
- es,占用9200和9300端口。
为了保留es数据,做了一个文件映射 执行后,可以看到如下反馈:

这里附加几个docker的用法:
查看容器的标准输出:
docker attach --sig-proxy=false myelk
停止容器:
docker stop myelk
启动容器:
docker start myelk
查看运行中的容器:
docker ps
进入容器命令行:
docker exec -it myelk /bin/bash
进入容器命令行,然后
cd /etc/logstash/conf.d/
vim 02-beats-input.conf # 注释掉ssl ,这个根据情况选择,我这里选择不启用ssl
vim myfilter.conf
输入如下内容并保持
filter {
json {
source => "message"
#target => "doc"
# message字段保留的就是整个json数据,如果把下面的语句生效,则流入es的数据中,没有message这个字段。具体效果可以自行做实验
#remove_field => ["message"]
}
# 这里是在处理日期时间,因为日志本身有时间,然后logstash会自行生成一个时间字段:@timestamp ,显然应该以日志里的时间为准。所以有如下配置:替换@timestamp字段的值为日志本身的时间。
date {
match => ["date","yyyy-MM-dd HH:mm:ss,SSS"]
target => "@timestamp"
locale => "cn"
timezone => "Asia/Chongqing"
}
}
重启logstash:
service logstash restart
如果提示stop fail,则再试一次。
单独测试logstash
启动关闭命令:
启动:service logstash restart
关闭:service logstash stop
进入容器,先执行:
service logstash stop
保证logstash已经停止
cd /opt/logstash
vim test-logstash.conf
输入以下内容:
input {
stdin {}
}
filter {
json {
source => "message"
#target => "doc"
#remove_field => ["message"]
}
date {
match => ["date","yyyy-MM-dd HH:mm:ss,SSS"]
target => "@timestamp"
locale => "cn"
timezone => "Asia/Chongqing"
}
}
output {
stdout {}
}
保存,然后执行:
bin/logstash -f test-logstash.conf
等待一会,直到看到如下字样:
The stdin plugin is now waiting for input:
[2018-12-29T07:57:25,159][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#<Thread:0x2d752f07 run>"}
[2018-12-29T07:57:25,210][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2018-12-29T07:57:25,458][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
然后直接在命令行输入一个json字符串,比如这里输入:
{ "date":"2018-12-28 18:54:04,052", "level":"INFO", "logger":"c.l.s.l.c.u.GeTuiPushUtils", "file_line":"GeTuiPushUtils.java:54", "msg":{"value":"初始化个推服务成功"}, "exception":"" }
然后会输出一个字符串,大致如下:
{
"msg" => { "value" => "初始化个推服务成功" },
"host" => "d6e142cd797d",
"level" => "INFO",
"exception" => "",
"file_line" => "GeTuiPushUtils.java:54",
"logger" => "c.l.s.l.c.u.GeTuiPushUtils",
"message" => "{ \"date\":\"2018-12-28 18:54:04,052\", \"level\":\"INFO\", \"logger\":\"c.l.s.l.c.u.GeTuiPushUtils\", \"file_line\":\"GeTuiPushUtils.java:54\", \"msg\":{\"value\":\"初始化个推服务成功\"}, \"exception\":\"\" }",
"@version" => "1",
"@timestamp" => 2018-12-28T10:54:04.052Z,
"date" => "2018-12-28 18:54:04,052"
}
如果是这样的,说明配置成功。然后按住 ctrl + c 停止测试。
其实到此应该就可以结束了。这里多贴一个配置,需求是:需要分环境(测试环境,生产环境)建立不同的es index。 这里直接贴上配置:
vim 30-output.conf
output {
if "ljd-test-log" in [tags] {
elasticsearch {
hosts => ["localhost"]
manage_template => false
index => "ljd-test-log-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
else if "ljd-prod-log" in [tags] {
elasticsearch {
hosts => ["localhost"]
manage_template => false
index => "ljd-prod-log-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
}
到此,elk服务准备好了,下一步使用filebeat搜集日志。
安装filebeat
下面需要在日志所在的机子上安装filebeat。
安装方法可以参照官网: https://www.elastic.co/guide/en/beats/filebeat/5.4/filebeat-installation.html
因为这里是centos 7系统,我的安装步骤是:
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.4.3-x86_64.rpm
sudo rpm -vi filebeat-5.4.3-x86_64.rpm
安装好后,默认的配置文件目录为:/etc/filebeat 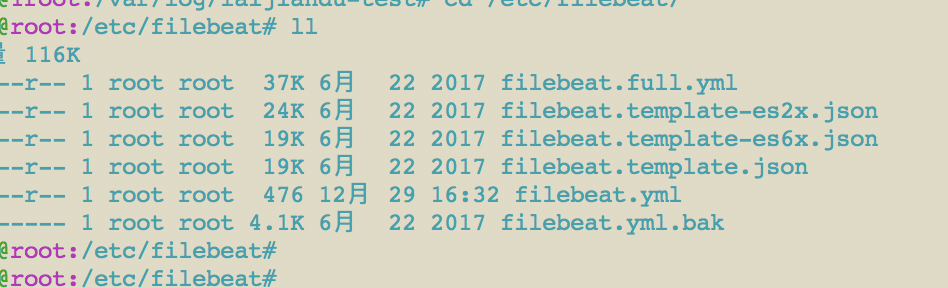
配置文件为 filebeat.yml ,我这里做了一个备份。把原来的 filebeat.yml重命名为了filebeat.yml.bak.
然后新建了一个filebeat.yml,内容如下:
filebeat:
prospectors:
-
paths:
- /var/log/laijiandu-test/*.log
tags: ["test-log"]
input_type: log
document_type: test-log
scan_frequency: 2s
harvester_buffer_size: 16384
max_bytes: 10485760
registry_file: /var/log/registry
output:
logstash:
hosts: ["logstashserverip:5044"]
worker: 1
bulk_max_size: 2048
compression_level: 3
index: filebeat
shipper:
logging:
files:
rotateeverybytes: 10485760
注意:上面配置中的tags需要和logstash中的对应起来。
启动filebeat: 不同系统的启动方法有所不同,具体可以参照官网: https://www.elastic.co/guide/en/beats/filebeat/5.4/filebeat-starting.html
我这里执行以下命令:
启动:
sudo /etc/init.d/filebeat start
停止:
sudo /etc/init.d/filebeat stop
以上步骤搞定后,就可以爽歪歪的使用 kibana了。
系统推荐
- MAT工具
- JVM垃圾收集器
- MySQL高可用
- 提取Docker镜像中的文件
- Spring RetryTemplate
- linux_no_space_left_on_device
- JVM异常处理
- AQS源码解读
- GitHub Workflow突然报错
- WebSocket SpringBoot Demo
- Linux
- 杂记
- 随机毒鸡汤:希望你明白,我凡事都看得开,但并不影响我记仇。
