线上JVM必须设置-XX:+HeapDumpOnOutOfMemory -Xloggc:gc_file_path -XX:HeapDumpPath=dump_path.hprof
对象空间分配机制
- 优先在Eden区进行分配
- 大对象直接进入老年代
假设大对象最后会晋升老年代,而新生代是基于复制算法来回收垃圾的,由两个Survivor区域配合完成复制算法,
如果新生代中出现大对象且能屡次躲过GC,那这个对象就会在两个Survivor区域中来回复制,直至最后升入老年代,
而大对象在内存里来回复制移动,就会消耗更多的时间。
假设大对象最后不会晋升老年代,新生代空间是有限的,在新生代里的对象大部分都是朝生夕死的,
如果让一个大对象占据了新生代空间,那么相比起正常的对象被分配在新生代,大对象无疑会让新生代GC提早发生,
因为内存空间会更快不够用,如果这个大对象因为业务原因,并不会马上被GC回收,那么这个对象就会进入到Survivor区域,
默认情况下,Survivor区域本来就不会被分配的很大,那此时被大对象占据了大部分空间,很可能会导致之后的新生代GC后,
存活下来的对象,Survivor区域空间不够放不下,导致大部分对象进入老年代,这就加快了老年代GC发生的时间,
而老年代GC对系统性能的负面影响则远远大于新生代GC了。
- 长期存活的对象进入老年代,年龄可以通过参数设置
- 动态年龄判断
Hotspot遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了survivor区的一半时,
取这个年龄和MaxTenuringThreshold中更小的一个值,作为新的晋升年龄阈值
uint ageTable::compute_tenuring_threshold(size_t survivor_capacity) {
//survivor_capacity是survivor空间的大小
size_t desired_survivor_size = (size_t)((((double) survivor_capacity)*TargetSurvivorRatio)/100);
size_t total = 0;
uint age = 1;
while (age < table_size) {
total += sizes[age];//sizes数组是每个年龄段对象大小
if (total > desired_survivor_size) break;
age++;
}
uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
...
}
可达性分析原理:三色标记
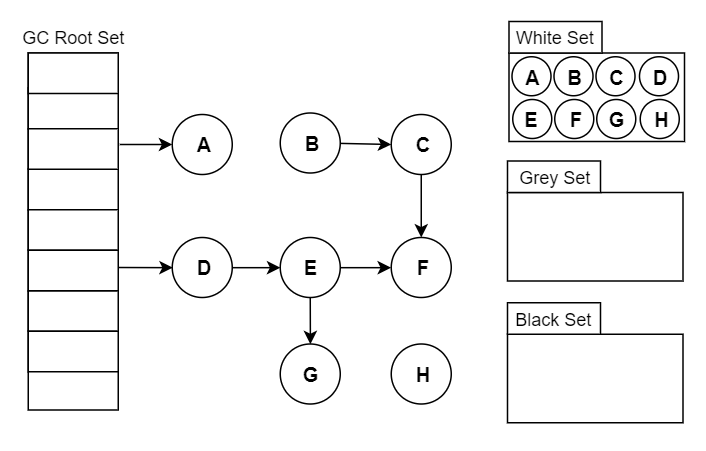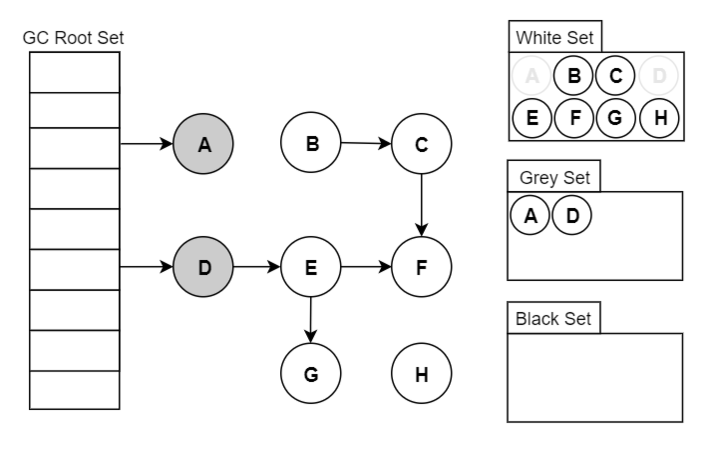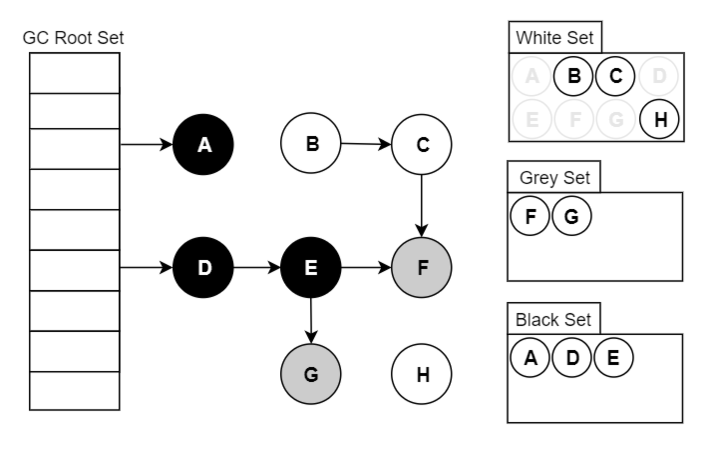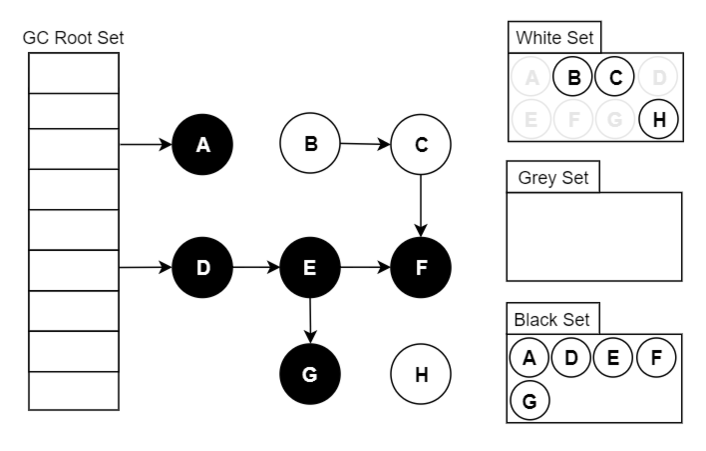
垃圾回收算法
垃圾回收算法,基本就是那么几种:标记-清除、标记-复制、标记-整理 在此基础上可以增加分代(新生代/老年代),每代采取不同的回收算法,以提高整体的分配和回收效率。
无论使用哪种算法,标记总是必要的一步。这是理算当然的,你不先找到垃圾,怎么进行回收?
垃圾回收器的工作流程大体如下:
标记出哪些对象是存活的,哪些是垃圾(可回收); 进行回收(清除/复制/整理),如果有移动过对象(复制/整理),还需要更新引用。
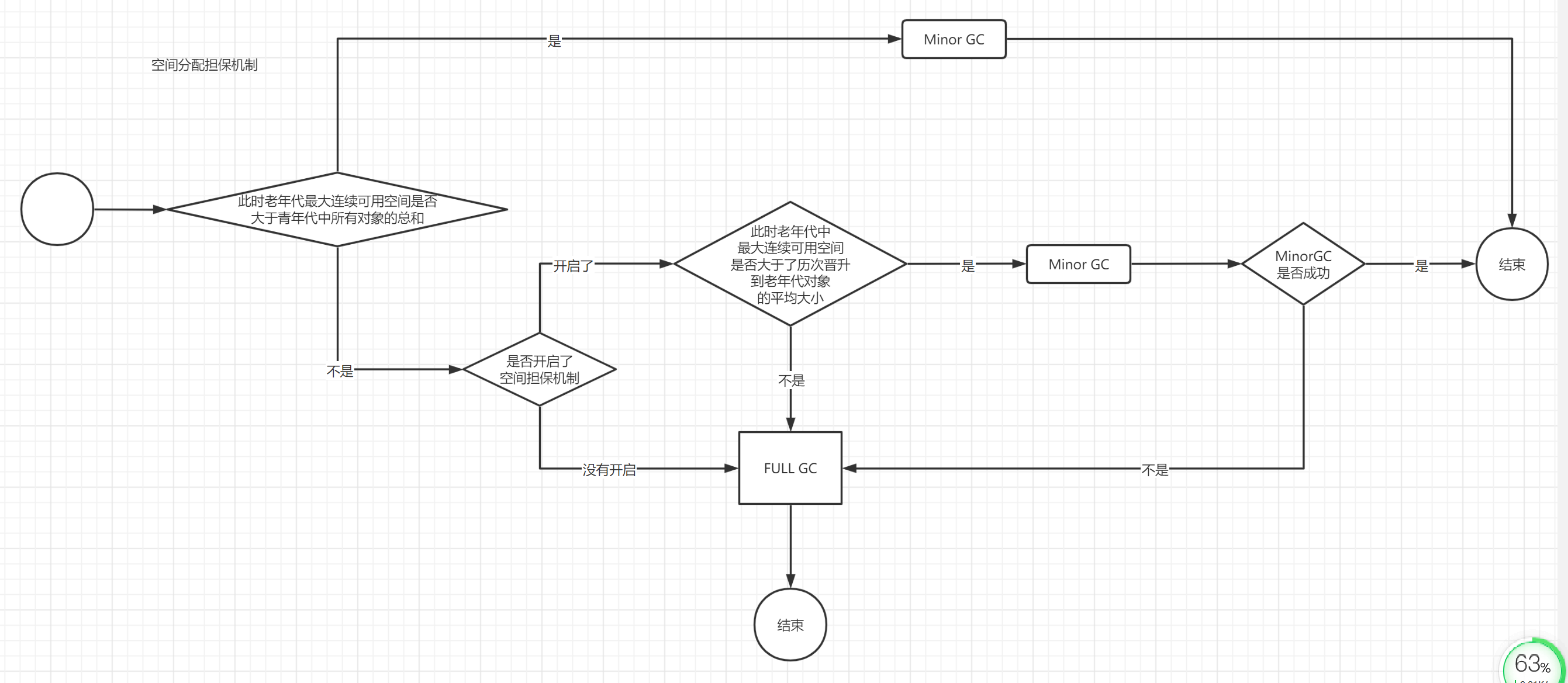
空间分配担保机制
在发生minor gc之前,jvm会检查老年代此时最大连续可用空间是否大于新生代所有对象的总和, 如果大于则直接进行minor gc(此时的gc是没有风险的), 如果小于,则会检查是否开启了空间担保机制。 如果没有开启,则会改为执行full gc.如果开启了空间担保机制, jvm又会检查老年代最大连续可用空间是否大于了历次晋升到老年代的对象的平均大小, 如果小于,则也会改为执行full gc。如果大于,则会尝试进行minor gc。 如果minor gc失败,会再进行一次full gc。
如何避免FullGC
FullGC是因为老年代空间不足而导致的gc.
- 条件允许情况下提升老年代容量(非本质方法),当然这不是有效方法。所以应该想办法让老年代的使用率趋于稳定或者增长尽量放缓。而根据对象分配的一些机制可以知道,还有如下几点:
- 尽量不要使用大对象
- 尽量不要长时间维持对象的引用
- 开启空间分配担保机制(默认是开启的)
GC三个算法
- 标记清除 (老年代采用)
- 复制算法 (新生代采用)
- 标记整理 (老年代采用)
serial,parnew,parallel scavenge :复制算法
serial old,parallel old : 标记整理
cms : 标记清除
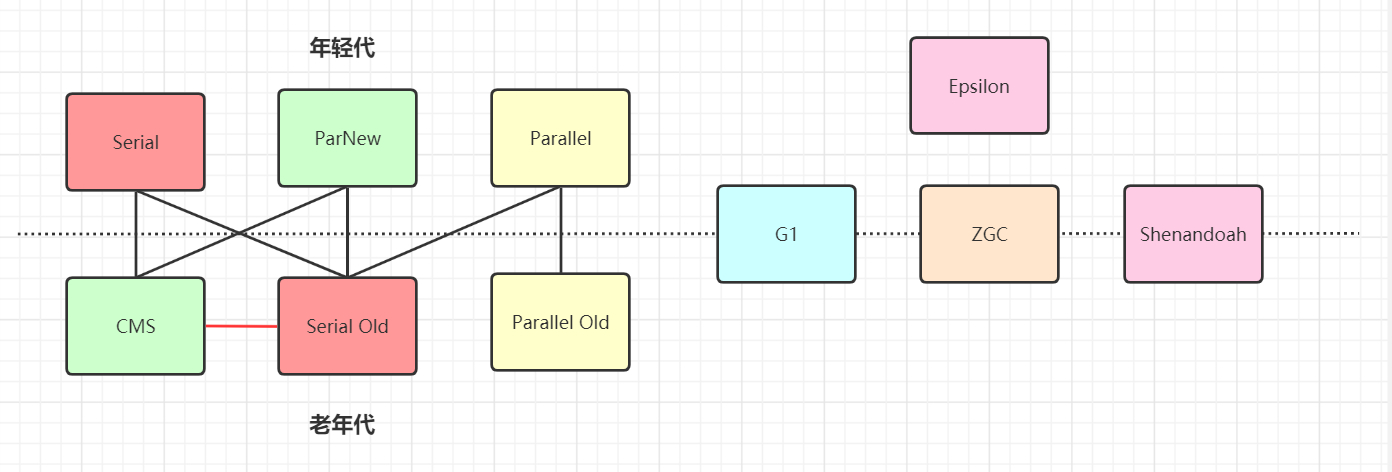
如果两个收集器之间存在连线,则说明他们可以搭配使用
ZGC
ZGC是JDK11引进的新一代垃圾收集算法
如何查看已启动的jvm实例使用的何种垃圾收集器
通过arthas里的jvm命令查看。
jdk1.8: 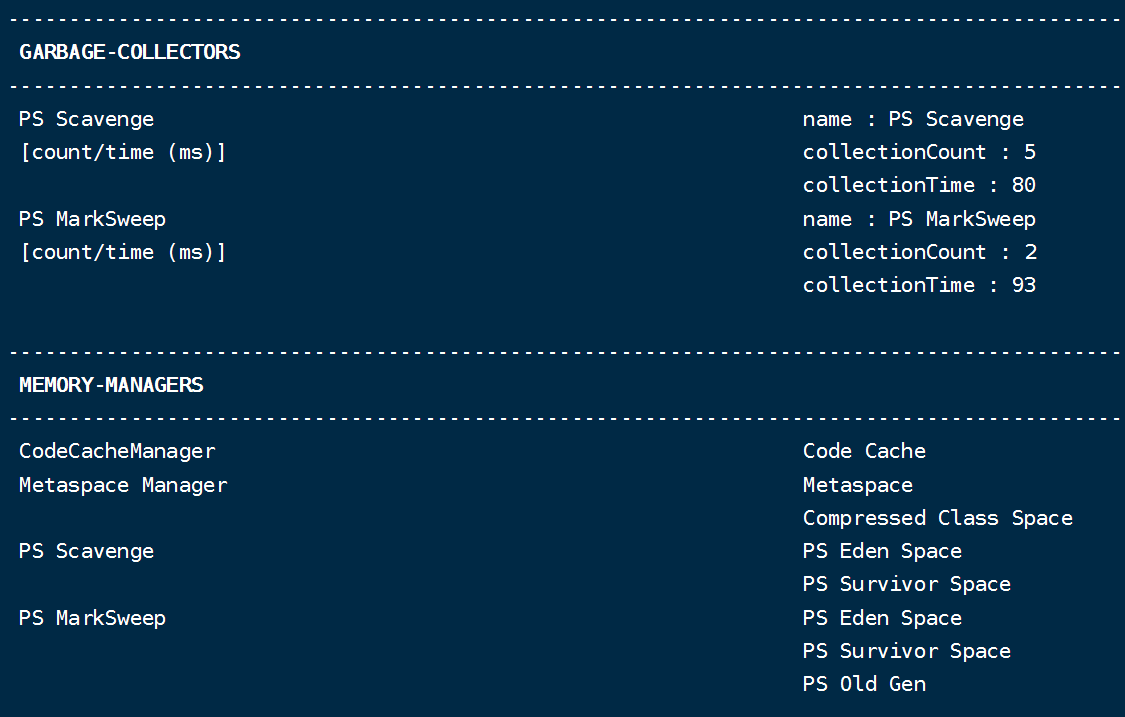 PS MarkSweep 这个收集器貌似不同的jdk代指不同的垃圾收集器
PS MarkSweep 这个收集器貌似不同的jdk代指不同的垃圾收集器
jdk11: 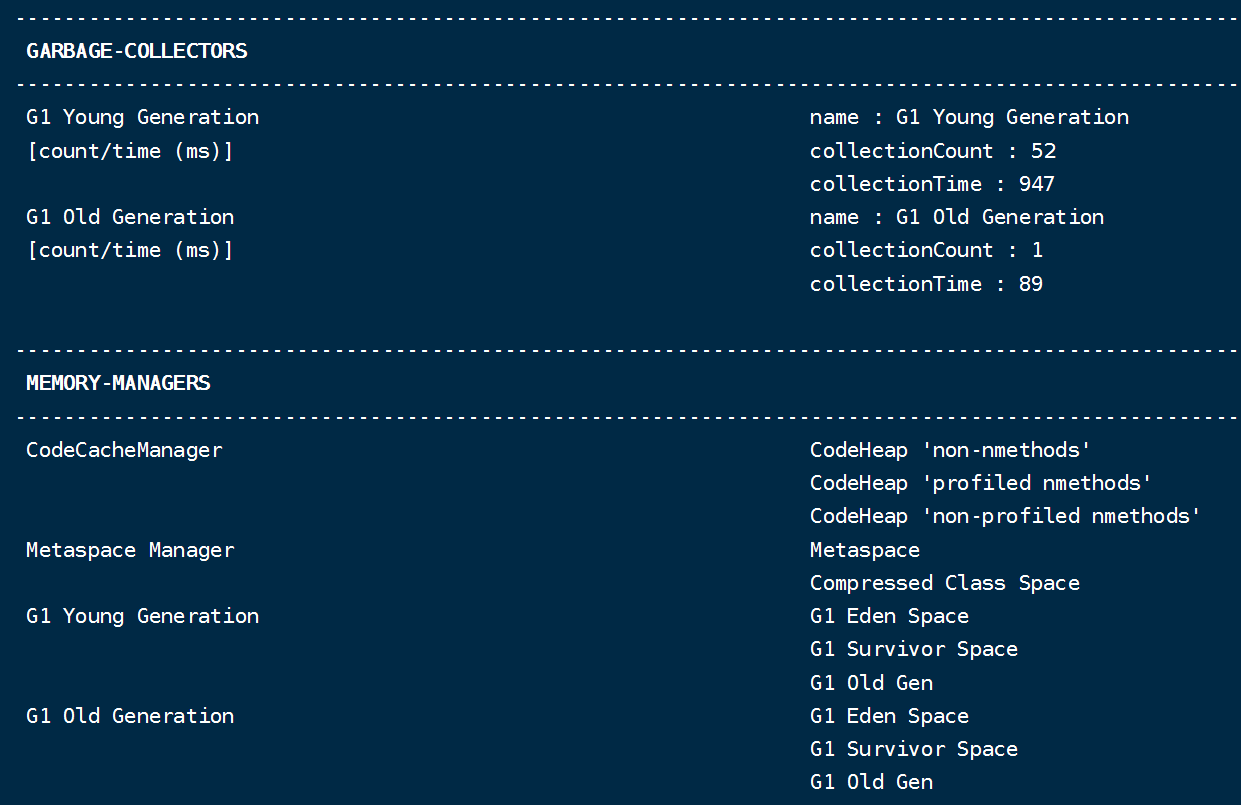
查看默认垃圾收集器
jdk8 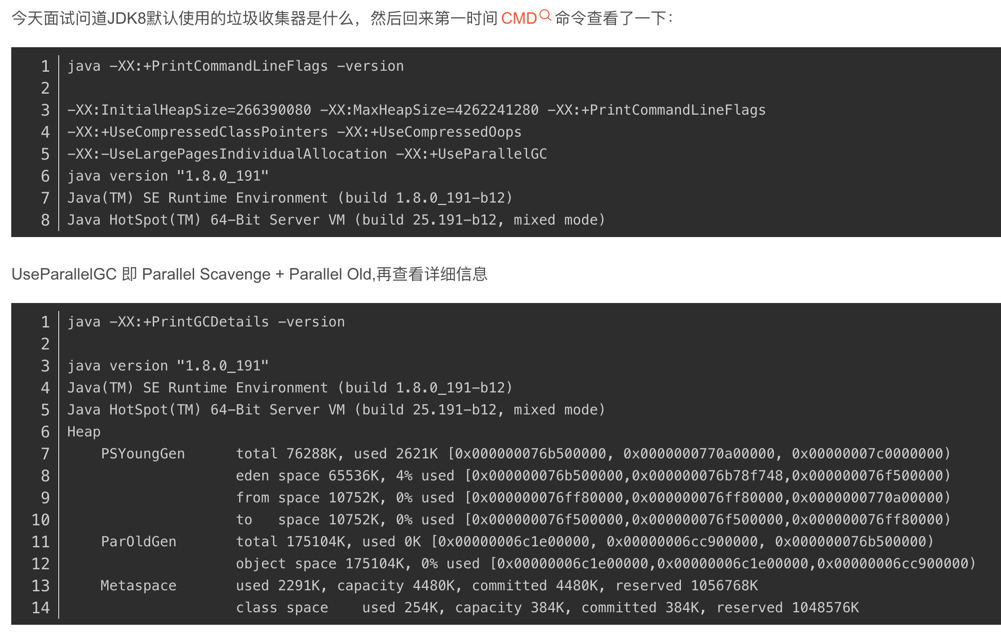
类加载器
- 启动类加载器 :jre/lib目录下指定名字的jar 或 -Xbootclasspath路径下的类 (注意是指定名字的)
- 扩展类加载器 :jre/lib/ext目录 或 -Djava.ext.dirs=path 路径下的类
- 应用程序类加载器 :classpath中的类库 ,ClassLoader类中getSystemClassLoader方法的返回值
- 要唯一区别一个Class对象,要通过ClassLoader实例+类全名。即便是同一个ClassLoader类的不同实例,他们加载相同的类,结果Class对象也不同。
逃逸分析
不是一种具体的代码优化手段,而是为其他代码优化手段提供依据的一种分析技术。
基本行为:判断一个对象是否存在方法逃逸或者线程逃逸。
分析对象动态作用域,一个对象被定义后,如果作为参赛传递给了其他方法,成为方法逃逸。如果被其他线程访问到,成为线程逃逸。
可以据此采用的优化手段有:
- 栈上分配 不存在方法逃逸
- 同步消除 不存在线程逃逸
- 标量替换 不存在逃逸
什么情况下会触发FullGC
minor gc前进行的一系列检查可能会导致full gc(空间担保机制)
system.gc,会建议执行fullgc
执行jmap -histo:live pid命令
老年代空间不足
永久代空间不足
避免使用大对象以及长期维持对象的引用
直接内存空间不足
谈谈你对面向对象的理解?
内存泄漏和内存溢出的区别?
两个都会报 oom 错误(会打印堆栈信息)
两者的区别就是内存中的对象是否有必要存在: 内存泄漏:内存中的对象不必要存在同时gc没办法回收导致了oom 内存溢出:内存中对象的存在是必要的,然后内存不足导致了oom
内存泄漏:根据堆栈信息或分析gc root引用关系找到相应的代码,分析是否可以不持有对象的引用。
内存泄漏可能存在的一个地方:ThreadLocal使用完毕后没有进行remove操作
ThreadLocal tl = new ThreadLocal();
线程A:
tl.set(new byte[1024*1024]);
线程B:
tl.set(new byte[1024*1024]);
用完后直接:
tl = null;
ThreadLocal
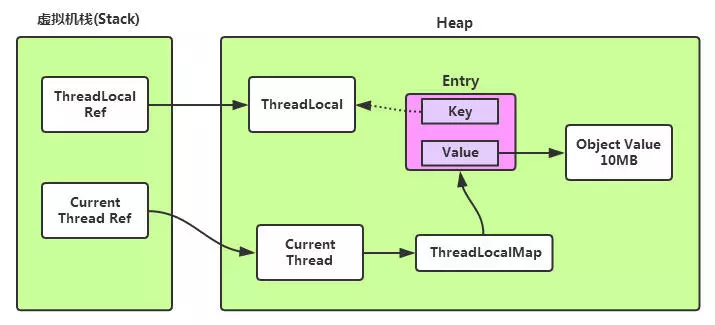
ThreadLocal 为什么会内存泄漏
ThreadLocal在ThreadLocalMap中是以一个弱引用身份被Entry中的Key引用的,因此如果ThreadLocal没有外部强引用来引用它, 那么ThreadLocal会在下次JVM垃圾收集时被回收。这个时候就会出现Entry中Key已经被回收, 出现一个null Key的情况,外部读取ThreadLocalMap中的元素是无法通过null Key来找到Value的。 因此如果当前线程的生命周期很长,一直存在,那么其内部的ThreadLocalMap对象也一直生存下来, 这些null key就存在一条强引用链的关系一直存在:Thread --> ThreadLocalMap-->Entry--> Value, 这条强引用链会导致Entry不会回收,Value也不会回收,但Entry中的Key却已经被回收的情况,造成内存泄漏。
InheritableThreadLocal
继承自 ThreadLocal,重写了很少的一部分代码 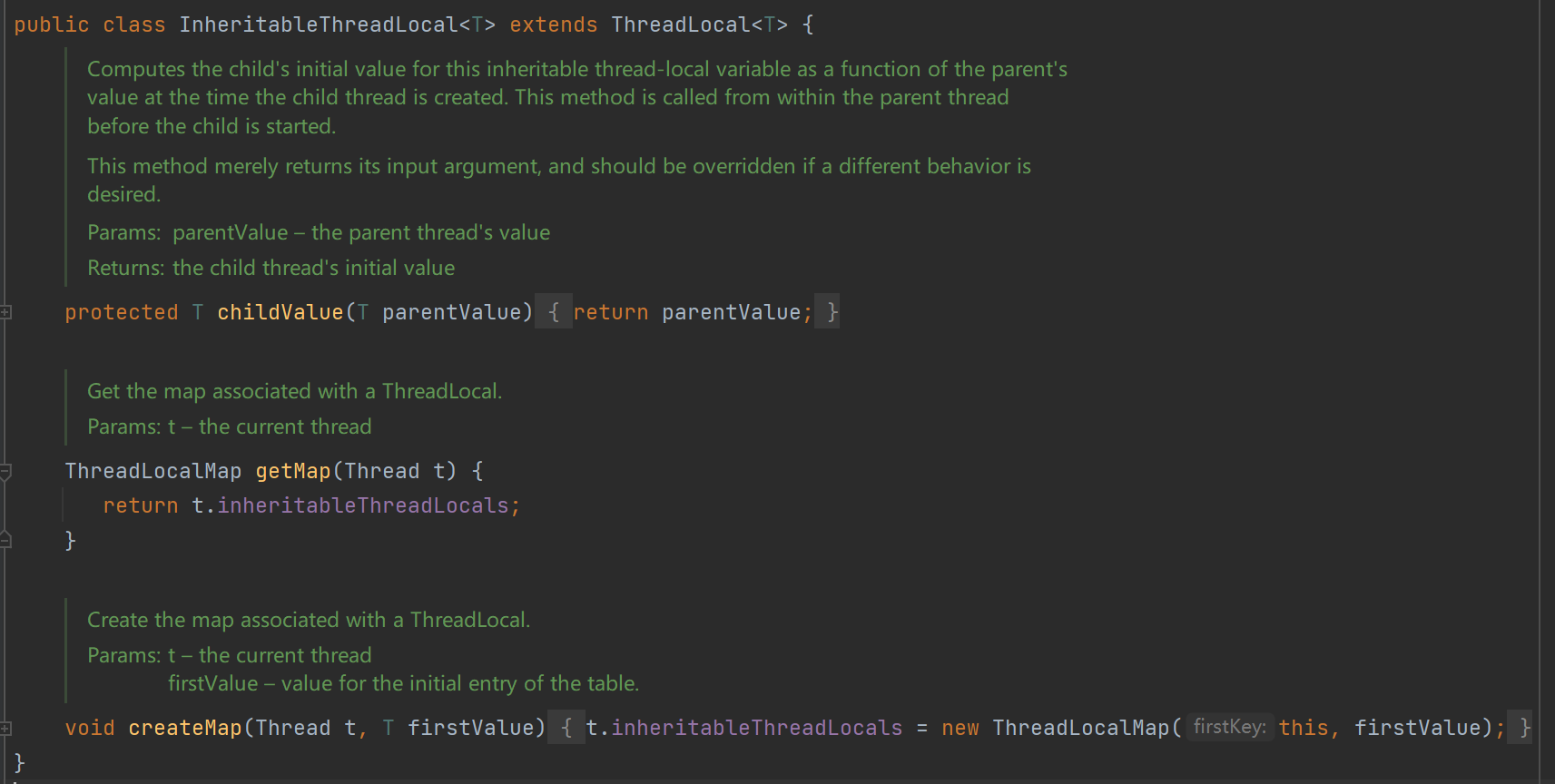
就是把返回的map修改为Thread类的inheritableThreadLocals变量
Thread类有两个ThreadLocalMap变量: 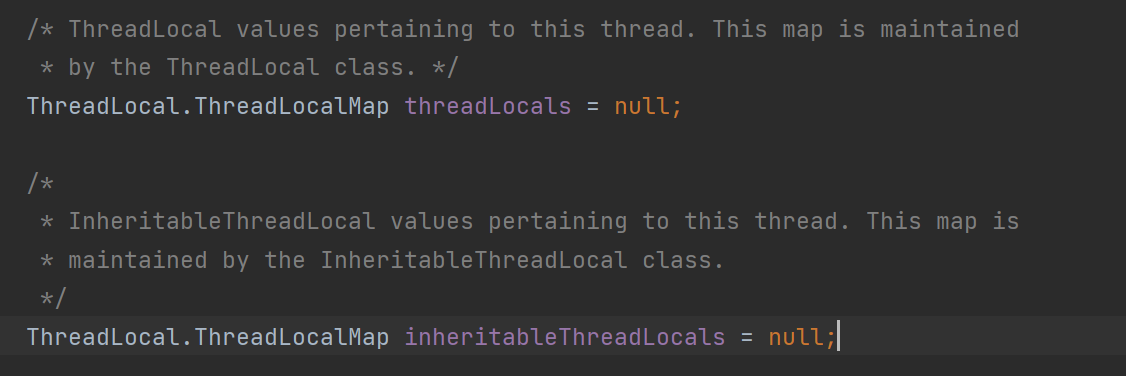
threadLocals : 给ThreadLocal类使用 inheritableThreadLocals :给 InheritableThreadLocal 类使用
作用:当某个线程创建子线程的时候,子线程可以继承当前线程中的inheritableThreadLocals中的值
怎么实现继承的? 就是在创建线程的时候,读取当前线程中 inheritableThreadLocals 变量的值, 新建一个ThreadLocalMap变量并赋值给新线程中的 inheritableThreadLocals 变量
弊端: 这种方式在线程只被创建和使用一次时是有效的,但对于使用线程池的场景下,由于线程被复用,初始化一次后,后续使用并不会走这个ThreadLocal传递的流程,导致后续提交的任务并不会继承到父线程的线程变量,同时,还会获取到当前任务线程被之前几次任务所修改变量值。
TransmittableThreadLocal
??? 有点难坑
既然都需要TtlRunnable,为啥不直接在new TtlRunable的时候,把当前线程中的 inheritableThreadLocal 变量的值复制一份 然后在执行真正的run方法前,吧复制下来的值放到当前执行线程中,这样当前执行线程就能获取到 父进程中设置的值,然后执行完真正的run方法后,把复制的值干掉就完了呀
发现OOM的时候怎么处理?
- 首先确定是内存泄漏还是内存溢出? (通过dump文件进行分析)
- 采取对应的措施
上面的方法只是针对在堆和永久代抛出的OOM情况,因为对外内存也会有抛出OOM的情况,而我们知道dump文件中不会对堆外内存进行dump。 抛出oom的时候,一般都会打印是哪块内存出现问题,如果是堆外内存,又分两种两种情况
- 提示不能创建新的线程:这种情况首先考虑创建的线程是否有必要,如果有必要,那么可以适当缩减堆或方法区的容量。
- 提示Direct buffer memory: 这种情况有点复杂,一般情况可以检查下是否开启了DisableExplicitGC参数,因为这个参数会影响gc对堆外内存的回收操作。 另外想办法找出代码中使用了堆外内存的地方,看是否有必要使用堆外内存或是否有存在没有释放的情况
内存溢出:调整相关的内存参数,一般情况下应该是增大
https://www.jianshu.com/p/b56033f1cb2c
jvm各个内存区域空间不足的时候报的异常信息:
- 本地方法栈+java方法栈:用Xss参数来控制(等同于-XX:ThreadStackSize=1024k)
//超出了Xss参数限制的情况
Exception in thread "main" java.lang.StackOverflowError
at com.misc.HeapOOM.f(HeapOOM.java:23)
at com.misc.HeapOOM.f(HeapOOM.java:23)
at com.misc.HeapOOM.f(HeapOOM.java:23)
//还有一种情况会报OOM: 创建大量的线程
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:714)
at com.misc.HeapOOM.main(HeapOOM.java:23)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147)
用于创建线程的空间大小:操作系统允许分配给进程的最大内存-分配给堆的大小-分配给永久代的大小。
所以如果线程数量是必要的,可以考虑减小分配给堆和永久代的空间大小。
- 老年代或新生代空间不足:用Xmx等参数控制
Dumping heap to java_pid1808.hprof ...
Heap dump file created [27632606 bytes in 0.475 secs]
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3210)
at java.util.Arrays.copyOf(Arrays.java:3181)
at java.util.ArrayList.grow(ArrayList.java:261)
at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:235)
at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:227)
at java.util.ArrayList.add(ArrayList.java:458)
at com.misc.HeapOOM.main(HeapOOM.java:17)
- 永久代空间不足:用PermSize,MaxPermSize等参数控制
java.lang.OutOfMemoryError: PermGen space
Dumping heap to java_pid645.hprof ...
Heap dump file created [504138731 bytes in 5.831 secs]
- 堆外内存空间不足:用MaxDirectMemorySize等参数控制,这个参数默认与Xmx相同大小
Exception in thread "main" java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:658)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:306)
at com.misc.HeapOOM.main(HeapOOM.java:21)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147)
6块区域(程序计数器,本地方法栈,java方法栈,堆,方法区,堆外内存)
https://www.cnblogs.com/paddix/p/5309550.html
两个方法栈超出Xss限制:抛StackOverflowError异常。
无法创建线程,堆,方法区,堆外内存:抛OOM异常。
HeapDumpOnOutOfMemoryError这个参数只对堆和方法区有用
堆外内存OOM时,不会执行Dump操作。
无法创建线程时的OOM,也不会执行Dump操作。
Dump得到的文件不会包含堆外内存的信息。
抛OOM的时候都会指出是哪快内存出现了问题。
仅仅通过Dump文件不能从dump文件中得出永久代、老年代、新生代的占用情况。
List<MappedByteBuffer> mbbs = new ArrayList<>(1000000);
for (int i = 0; i < 1000000; i++) {
RandomAccessFile raf = new RandomAccessFile("testfile", "r");
MappedByteBuffer mbb = raf.getChannel().map(FileChannel.MapMode.READ_ONLY, 0, Integer.MAX_VALUE);
raf.close();
mbbs.add(mbb);
}
java.lang.OutOfMemoryError: Map failed
哪些情况下回进行初始化操作?
- new : new 对象的时候
- getstatic : 引用某个类的静态字段(如果是final字段,不会进行初始化)
- putstatic : 设置某个类的类的静态字段
- invokestatic : 调用某个类的静态方法的时候 (静态导入不会执行初始化)
- 对某个类进行初始化的时候,如果父类没有初始化,先对父类进行初始化
- 对某个类进行反射调用的时候 (包括使用Unsafe.allocateInstance方法,使用这个方法会执行初始化,但不会执行构造方法,也不会执行仅仅用大括号括起来的代码(没有static))
- 虚拟机启动时指定的那个主类会进行初始化。
仅仅导入(包括静态导入)某个类,是不会执行类的初始化操作的。
类的生命周期
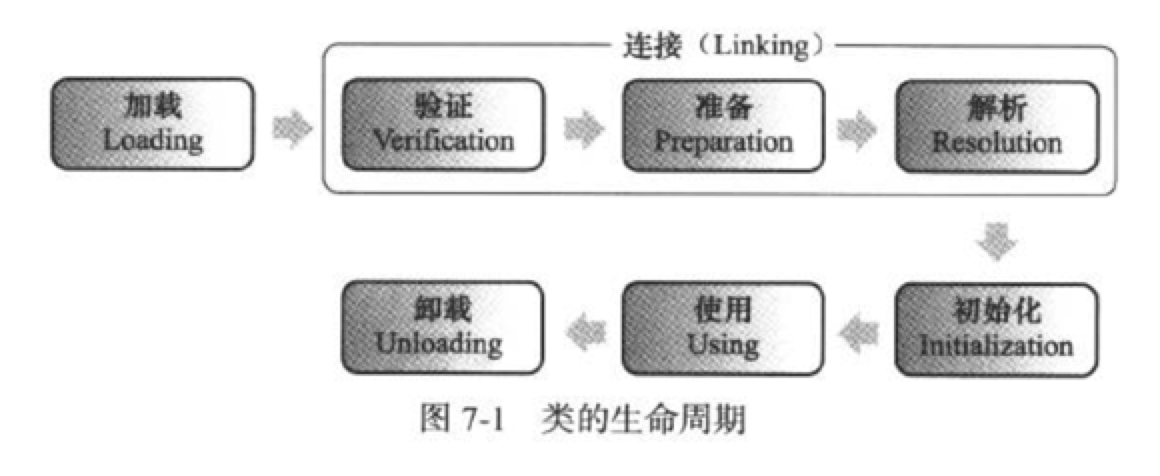
加载、验证、准备、解析、初始化、使用、卸载
加载、验证、准备、初始化和卸载这五个阶段是依次开始的,后一阶段的开始不依赖前一阶段的结束。也就是说上一个阶段没有结束的情况下,后一个阶段也可能开始。
JAVA的内存模型
我的理解就是JVM针对数据在jvm里的访问修改等操作定义的一系列规则。
主要围绕三个特性展开:原子性,可见性,有序性
- 可见性:当一个线程修改了某个共享变量的值,其他线程能立刻得知这个修改。
- 有序性:就是禁止指令重拍,保证代码执行顺序就是代码的书写顺序。
- 原子性:不可分割
各个线程拥有各自独立的工作内存,互相是不可见的。线程间在这样一条规则的约束下通过主内存来进行通信。
JMM规定所有的变量都存储在主内存中(不包括线程私有变量),每个线程会在自己的工作内存中保存一份相关变量的一份副本,线程对变量的所有操作都必须在各自的工作内存中完成,不得直接读写主内存中的变量,线程间变量的传递均通过主内存来完成。
volatile变量依然有工作内存的拷贝,不过有特殊的访问规则,站在线程的角度就好比直接操作了主内存一样。
JMM规定了8中工作内存与主内存之间的交互操作,每个操作都是原子的,不可再分的(针对double,long型数据有些平台允许例外,商用jvm都是原子的不可分的)
lock : 作用于主内存中变量,将变量标记为某个线程独占状态
unlock : 和lock相反
read : 作用于主内存中变量,将主内存变量传输到工作内存中
load : 作用于工作内存中变量,将read操作读取到的变量值放入工作内存的变量副本中。 (read和load的也许可以理解为 a=b,先读取b的值,然后赋值给a)
use : 作用于工作内存中变量,将工作内存中的变量传递给执行引擎
assign : 作用于工作内存中变量,将执行引擎输出的变量赋值给工作内存中的变量
store : 和read相反,左右于工作内存变量,将工作内存中的变量值传输到主内存中
write : 和load有点类似,作用于主内存中变量,将store读取到的变量值放入到主内存变量中。
JMM针对这8中操作还规定了一些额外的约束:
read/load和store/write必须成对顺序使用,但中间可以插入其他操作
不允许丢弃最近一次assign操作的值,也就是说最近一次工作内存中变量值发送改变后必须同步回主内存。
如果没有发生assign操作不得回写到主内存
一个新的变量必须在主内存中诞生,也就是说use之前必须执行load,store之前必须执行assign。
如果同一线程多次lock同一个变量,则必须执行相同次数的unlock操作,然后变量才会解锁
lock操作会清空工作内存中此变量的副本,因此执行引擎使用这个变量前,必须先执行load或assign操作。
只能unlock被自己lock住的变量
unlock之前,不得将变量同步回主内存,也就是必须执行store,write操作后才能执行unlock。
普通变量和volatile变量的区别? volatile变量能保证可见性和有序性,而普通变量不可以。
- volatile变量,
- volatile变量
- 1.2两条使得volatile变量能保证可见性,同事volatile变量还能保证有序性,而普通变量不可以。
volatile变量适用的场景有哪些?
- 对volatile变量的修改不依赖当前的值
可见性是如何实现的?
每次 use 前都会执行 read,load操作来刷新工作内存值。而普通变量不会。
每次发生了assign操作后会立即执行store,write操作,而普通变量发生assign操作后可能不会立即执行store,write操作。
- 有序性是如何实现的?
规定use的前一个动作就是read,load;
read,load的后一个动作就是use;
针对同一个变量,这三个动作是连续的,中间不能插入其他动作。
规定assign的后一个动作就是store,write;store,write的前一个动作就是assign.
- final,volatile,synchronized对三个特性的区别?
- final : 原子性、有序性、可见性
- synchronized : 原子性、有序性、可见性
- volatile : 有序性、可见性
Java里的四种引用
- 强 无论何时,只要有强引用关系的对象,都不会被垃圾回收器回收掉,如果内存不足的时候,直接报错
- 软 有软引用关系的对象,当内存即将不足的时候,会被垃圾回收器清理掉;
- 弱 有弱引用关系的对象,只能活到下一次垃圾回收的时候,也就是,只要发生了一次垃圾回收,那么弱引用关系的对象就被清理掉了
- 虚 最弱的引用,我们甚至无法通过虚引用获得关系对象的信息。它的唯一作用,就是在垃圾回收的时候,能够将相关信息放在一个队列中。进而我们可以用这个队列获得相关信息。
扩展阅读:https://www.cnblogs.com/zhouzhiyao/p/13173613.html
哪些对象可以作为gc roots
- 虚拟机栈中引用的对象
- 本地方法栈中引用的对象
- 方法区中静态属性引用的对象
- 方法去中常量属性引用的对象
系统推荐
- JVM垃圾收集器
- KVM 虚拟机安装
- MongoDB高可用
- Hadoop 一
- 正则表达式匹配第几个符号问题
- 高可用通用方案
- Spring Boot升级到2 6 x踩的坑
- Java语言完成notion笔记备份
- PGSQL的json和 jsonb 读写性能测试
- RocketMQ
- 批量替换文件名中的指定字符串
- SpringCloud总体认识
- 随机毒鸡汤:戴帽子不是为了凹造型,只是因为帽子下,藏了一颗几天没洗的头。
