持久化
RDB
AOF
AOF重写
- cow机制(copy on write)
- 从7.0.0开始,aof文件分为base file和增量file.

- 从7.0.0开始,当开始执行aof rewrite的时候,主进程就会往一个新的增量aof文件写入数据,同时子进程就会依照现在内存中的数据创建一个新的base file。当子进程完成aof rewrite后,redis会进行一个原子操作使得新的base file生效。 感觉7.0.0的重写过程比之前的过程简单直接有效多了

重写过程总结:
版本>= 7.0
- fork一个子进程
- 主进程开始往新的一个增量aof文件中写入数据
- 子进程根据当前内存的数据生成一个新的base file
- 如果重写失败,原来的base file和原来的增量文件以及新的增量文件仍能代表当前数据的状态
- 如果重写成功,主进程会收到一个signal,然后通过一个原子操作使得新的base file和新的增量文件生效
- 清除之前的base file以及失效的增量文件

Untitled 版本<7.0
- fork一个子进程
- 子进程开始根据当前内存数据生成一个新的aof文件
- 主进程会把这个期间收到的写命令写入一个缓冲区(当然也会同时写到aof缓存,和之前的动作一致)
- 如果子进程重写失败,当前正在使用的aof文件也能正常使用,所以安全
- 如果重写成功,主进程会把之前累计的缓冲区内容追加到新的aof文件中,然后原子的重命名aof文件

主从架构
- 主从架构可以实现读写分离,减轻master服务器的压力
- 但无法解决海量存储问题
- 无法做到高可用,一旦master宕机,无法自动failover
哨兵模式
哨兵模式就是 监工+主从模式 ,哨兵就是监工,监工的工作主要有以下3点:
监控功能: 能监测集群内所有节点(包括master、slave以及其他哨兵节点)
故障转移:当master挂掉后,由哨兵节点来选举新的master节点并进行转移
配置中心:当故障转移发生后,通知client端新的master地址
哨兵节点数至少3个
哨兵模式只能保证高可用,并不能保证数据不丢失
为什么哨兵节点至少为3个
其实不一定,需要看具体怎么部署的,如果按照下面的方式进行部署:
+----+ +----+
| M1 |---------| R1 |
| S1 | | S2 |
+----+ +----+
M1表示Master,R1表示从节点,S1,S2表示两个哨兵
此时,quorum为1,表示只要一个哨兵认为某个节点宕机了,就可以认为这个节点客观宕机了。同时 majority为2,表示至少需要两个哨兵的授权才能执行主备切换
如果此时m1宕机了(非m1所在服务器宕机),此时还有S1/S2都还活着,所以能正常执行主备切换
但如果m1所在服务器宕机,那么S1也宕机了,此时就只有S2这一个哨兵活着,自然不能执行主备切换
- quorum:需要多少哨兵都认为某个节点宕机时,这个节点才会被标记为客观宕机
- majority:需要多少哨兵的授权才能执行主备切换(实际上去quorum和majority的较大值)
经典的 3 节点哨兵集群
+----+
| M1 |
| S1 |
+----+
|
+----+ | +----+
| R2 |----+----| R3 |
| S2 | | S3 |
+----+ +----+
此时:quorum 为 2,majority 为 2,所以如果m1所在的服务器宕机,那么还有两个哨兵节点,满足主备切换的哨兵数量要求
主观宕机
如果某个哨兵认为一个master宕机了,首先是主观宕机。
判定过程:哨兵会ping这个master,如果master在一个阈值时间内没有发送pong信息,那么这个哨兵就认为这个master主观宕机了
客观宕机
如果quorum个哨兵都认为某个master主观宕机了,那么这个master就是客观宕机了
判定过程:当某个哨兵认为某个master主观宕机后,就会~~通过gossip协议(没验证,应该不是这个协议,应该是通过pub/sub机制来完成通知)~~ 通知其他哨兵。当某个哨兵在一定时间内收到quorum个哨兵也认为这个master主观宕机的消息,那么就会被标记为客观宕机
哨兵自动发现机制
主要运用就是redis的pub/sub机制,具体过程如下:
每个哨兵会监听自己所监控的所有master/slave节点的 __sentinel:hello__ 频道,同时每隔一段时间就会把自己的host、ip、runid、以及对这个节点的监控配置发送到这个频道,其他哨兵就会收到这个消息,从而自动发现其他哨兵
主备切换大致过程
当quorum个哨兵认为某个master宕机后,并且majority个哨兵都同意进行主备切换,那么会从quorum个哨兵中选举一个哨兵来执行主备切换。会从所有的slave节点中选择一个slave成为master.
考虑的点有下面4个样子:
- 和master断开连接的时长
- slave的优先级(配置文件可以指定,越小优先级越高)
- offset
- runid
slave过滤:如果某个slave与master断开连接的时长超过了一定阈值,那么这个slave就没有资格成为master
对过滤后的slave节点按照上面的2、3、4点进行排序,然后依次尝试进行切换
版本号
执行主备切换过程中,会有个版本号,没太搞明白,这里贴出截图

Redis Cluster
扩展阅读: https://redis.io/docs/reference/cluster-spec/
扩展阅读: https://redis.io/docs/management/scaling/
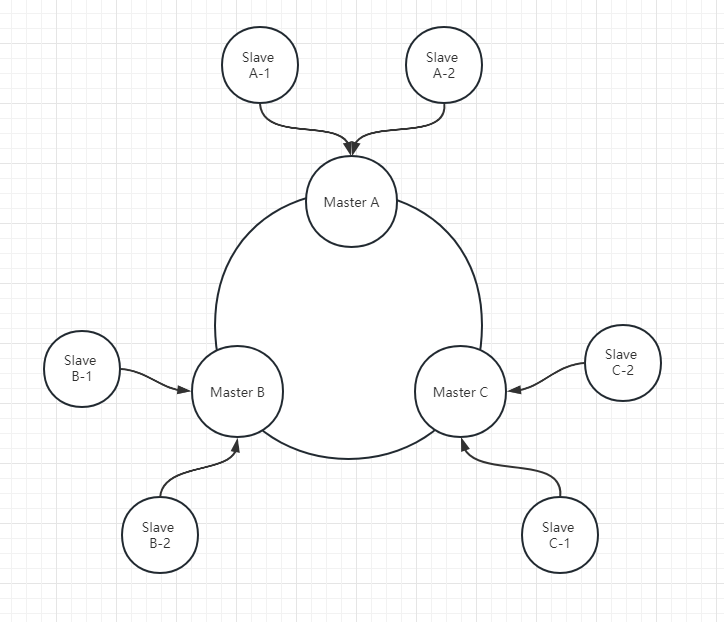
- 节点间通信没有采用普遍使用的tcp,而是tcp-bus,是一种自组织网络
- 节点间通信协议是 gossip 协议(没去研究,说也是一种共识算法,模拟流行病的传播)
- 集群中每个节点都和其他节点保持连接,并发送各种信息包
- 集群并不能代理请求,所以客户端的情况有可能会被重定向,有点类似http的重定向,所以理论上客户端可以给集群中的任意节点发送请求。但为了提高性能,客户端可以缓存key和node的隐射关系
- 固定有2^14=16384个hash槽,每次采用crc16算法对key计算hash值,然后对16384取模得到某个hash槽,然后根据槽和节点的映射关系,最终路由到某个节点上
- 客户端可以通过hash tag的方式来让某个key的请求固定走某个hash槽
- 所有节点都各自持有一份元数据,如果发生变更,则通过gossip协议告知其他节点
- 比如3个master,每个master后面又挂多个slave
JedisCluster客户端工作过程
- 每个jediscluster客户端都会在本地维护一个hash slot到node节点的隐射表
- 当对某个key执行操作的时候,会先在本地计算出这个key的crc16值,然后对2^14(16384)取模,得到hash slot,然后根据hash slot到node节点的隐射表,找到对应的node节点(可能正确,可能错误)。
- 然后对这个node节点发起请求,接收到请求的node节点发现这个slot恰好在自己这边,则执行请求。否则返回moved或ack
- 如果客户端收到moved请求,则更新本地的映射表,并重新发起请求。
- 如果客户端5次尝试都不成功,则报错
主备切换大致过程
其实过程和哨兵模式下的主备切换大致相同,都可以分为下面几步
先标记客观宕机
如果一个节点认为某个master节点宕机了,则是主观宕机。
如果过半节点都认为这个master节点宕机了,则是客观宕机。(通过gossip协议通讯)
slave过滤
对宕机的master节点的所有从节点进行过滤
如果从节点与master节点的断开时间超过一定阈值,则这个从节点没有资格成为master节点
执行主备切换
对剩下的从节点进行排序,排序维度有 priority、offset、runid。然后依次尝试进行主备切换
备注:上面整理的内容对一些细节肯定是不对的,这里只是为了从整体上了解其中的原理或过程
Twemproxy
扩展阅读:https://github.com/twitter/twemproxy
Codis(基本废弃了)
github都4年多没更新了 , https://github.com/CodisLabs/codis
题外话
分享一个查看linux函数、系统调用的好网站: https://linux.die.net/man/
之前不理解什么section 2 ,看了上面的网页就明白了,原来Linux用户手册分为了好几部分,section 2就是第二部分,里面包含的是系统调用相关的介绍(为之前的愚蠢感到可笑 😂)
- 高可用的根部就是:冗余 + 分片
- 至于怎么实现冗余,那就不尽相同
系统推荐
- Spring Cloud Gateway收到的是http请求,但schema却是https
- Git合并多个提交并push到远程仓库
- PostgreSQL定时备份
- Censys搜索引擎学习
- 如何安装Google BBR
- ShadowsockServerUpdatePort
- MySQL索引
- 多台centos服务器,文件互相备份
- JVM杂项
- vuepress-theme-hope使用心得
- Linux dev shm目录
- 表单重复提交解决方案
- 随机毒鸡汤:我女朋友家真的好穷,那天我说想去她家看看,她说连门都没有。
