Java 自带的动态代理实现原理。
使用方法
核心方法:
Proxy.newProxyInstance(ClassLoader cl,Class[] interfaces,InvocationHandler iv)
如果是我会怎么实现newProxyInstance这个方法
主要思路:
第一步:生成字符串形式的代码
第二部:把字符串形式的代码编译为Class对象。
第一步
无非就是字符串的拼接。如果我们按照正常写代码的步骤能写出来,那么这一步也就没有问题。每个生成的方法都调用invocationHandler的invoke方法。
invoke方法需要三个参数:Object Methond args
正常写代码应该是这样子:
public interface DemoInterface {
String speak(String str);
}
public class DemoProxy implements DemoInterface {
private InvocationHandler iv;
public DemoProxy(InvocationHandler iv){
this.iv = iv;
}
public String speak(String str){
Method m = this.getClass().getDeclaredMethod("speak",String.class);
Object[] args = new Object[]{str};
return this.iv.invoke(null,m,args);
}
}
第二步
字符串形式的代码有了,下面就是编译为Class对象。
jdk提供了JavaCompiler这个功能能完成这个工作。具体代码不用太关心,只需要知道可以做到这个工作就可以了。确实需要的话,百度下JavaCompiler就能知道。
Proxy类的实现方式
其实思路大同小异。
Proxy的实现也是反射获取接口中定义的方法,然后根据class文件的二进制格式来生成一个byte数组(代表的就是代理类的class文件二进制),然后通过类加载器装载为一个Class对象
红黑树(5个特征,简化为4个)
- 根黑叶黑
- 父红子黑
- 非红即黑
- 黑相同
简单请求和复杂请求
用户态和内核态(用户空间、内核空间)
- 用户态线程和内核态线程存在一个映射模型(one-to-one、many-to-one、many-to-many),linux和jvm采用的是one-to-one
- 用户态和内核态之前的切换,也就是用户态线程和内核态线程之前的切换,那么就会涉及到线程的切换,所以用户态和内核态之间的切换是有代价的
- 切换原因:
- 系统调用(软中断)
- 外设中断
- 异常
mongo与mysql如何保证数据一致性
比如某个请求,会同时更改mysql和mongo里的数据,如何保证同时成功或同时失败
方案: 需要事务的时候,把对mongo更新操作转换为对mysql的操作。 然后通过canal把mysql中mongo的操作在mongo中进行重做
tcp 可靠字节流连接
三次握手 a-->b: 我要和你通话(syn) b-->a: 好的,我准备好了(syn+ack) a-->b: 好的(ack)
网络io
内核要做的事情:
准备数据到来
复制数据到用户内存
虚拟内存背后可能是物理内存,也可能是磁盘
每个进程有各自的page table,也就是每个进程都有各自的虚拟内存
32位机子,虚拟内存大小为4G,64位机子,虚拟内存大小为2^34G
虚拟内存可以划分为两部分,高1/4的内存,称之为内核空间,剩下的虚拟内存称之为用户空间
谈虚拟内存就要谈进程,脱离进程谈虚拟内存没有意义
内核空间总是驻留在物理内存中,当新建进程或进程消亡的时候,在进程对应的page table中与虚拟内存进行映射
内核空间中,有些是进程共享的,有些是进程私有的,也就是说不同进程的内核空间可能映射到相同的物理内存上
共享的内核空间:内核数据,内核代码等
私有的内核空间:内核栈,页表等
DMA 的全称叫直接内存存取(Direct Memory Access),是一种允许外围设备(硬件子系统)直接访问系统主内存的机制
直接内存和直接io不是一回事,直接内存是直接操作物理内存,直接io是直接操作io设备。直接io可以跳过page cache机制,也是一种实现零拷贝的方案(jvm不支持)
mmap: 是将一个进程的地址空间中的一段虚拟地址映射到磁盘文件地址,page cache仍会参与进来
零拷贝并非完全没有拷贝,只要相对于传统的io方式少了一次或多次拷贝都可以称之为零拷贝
mappedbytebuffer: 可以理解为是在内核空间开辟了一块内存,应用程序可以读写这块内存,同时和磁盘文件有关联,底层采用的mmap实现
执行mmap后,会马上分配虚拟内存,但不会马上映射物理内存。(个人猜测:为什么rocketmq的commitlog文件映射的是1g大小,是因为考虑到一些32位服务器的虚拟内存最大也就4G,用户空间还只有3G,如果分配过大,虚拟内存都不够了,更不谈物理内存是否足够 )
进程向系统申请内存 系统检查进程的虚拟内存是否使用完,有剩余则分配 系统分配物理内存
虚拟内存分为内核空间和用户空间
- 在linux系统中线程的本质是进程,然后每个进程直接的内存不能互相访问,但实际情况是可以互相访问的,这是怎么做到的?
关于用户态和内核态
- 同一个线程不能在用户态和内核态直接切换,从创建到消亡,只能在一个状态下工作
- 谈到用户态和内核态,都是只用户态线程和内核态线程
用户态到内核态的三种方式:
- 系统调用,本质也是中断,不过是软中断
- 异常
- 外设中断
page cache: 文件系统的缓存。
- 应用程序发起读文件操作
- 操作系统检查page cache中是否有,有则直接返回
- 如果没有,则由dma进行磁盘读操作
- dma把数据从磁盘读入(复制)到page cache (dma copy)
- cpu介入,把
rocketmq
异步、解耦、消峰(个人认为主要用途是消峰,解决速度不匹配的问题,其他两个左右都有代价更小的替代方案)
一个topic可以包含多个队列
同一个队列只能被同一个消费组里一个消费者消费
一个消费者可以同时消费多个队列
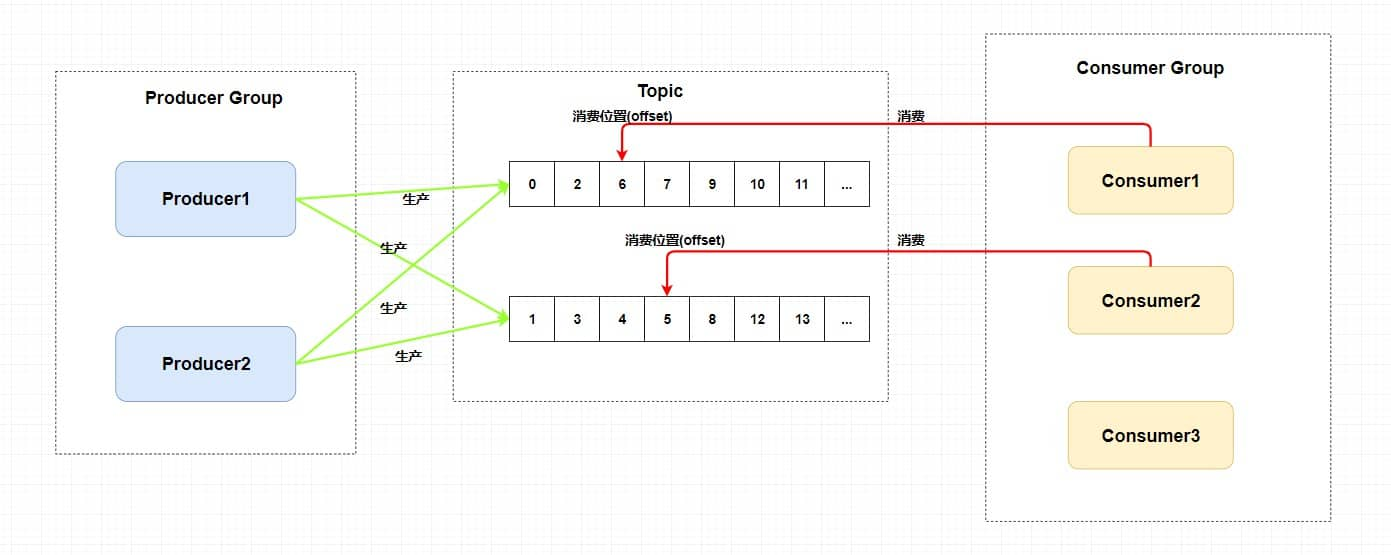
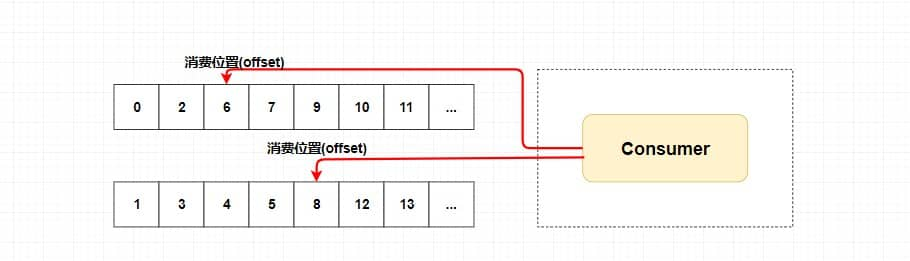
消费者组里的消费者个数最好大于等于主题里队列的个数
如果业务要求消费顺序和发送顺序要一致,这种情况个人觉得一个topic多个队列和一个topic一个队列没啥区别。但如果不要求一直,那么建议一个topic多个队列
rocketmq的事务消息,是指本地事务和消息发出去的一致性,也就是如果本地事务执行成功,那么消息就能发到brocker并被消费者正常消费。但如果本地事务执行不成功,那么消息就不会被消费者消费到。是指的这个
rocketmq的官方架构图
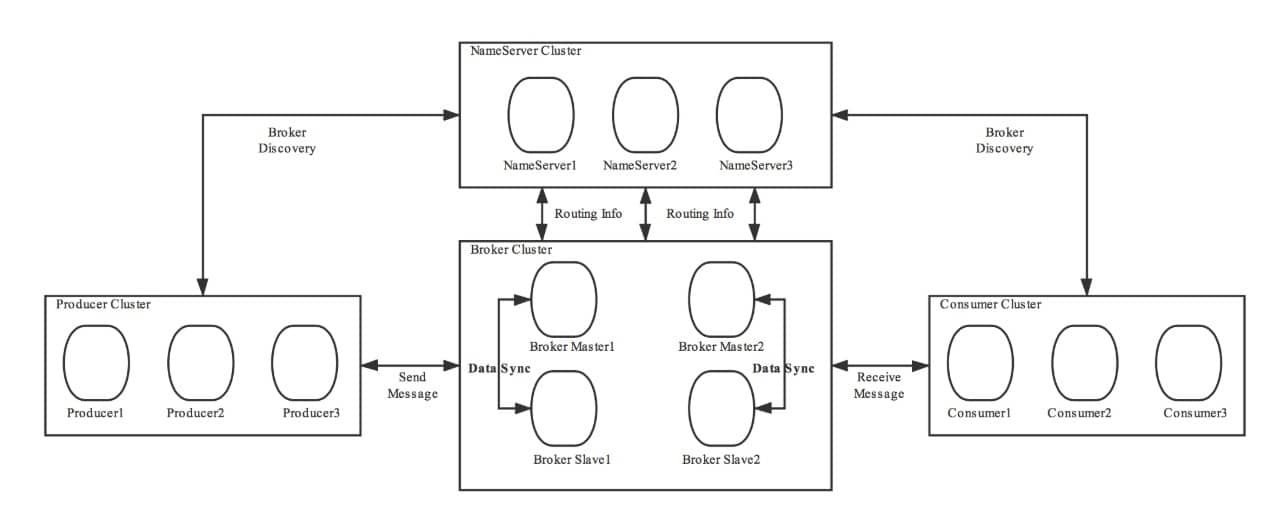
rocketmq的主从结构中,当master挂了后,slave只能提供读服务,不能提供写服务(这是老版本了,新版本用raft算法能选举新的leader节点)
docker 容器 oom,异常重启
排查原因发现:
- xmx设置的内存大于了分配给这个容器的内存
docker events 命令
通过docker events命令可以查看各种事件 扩展阅读:https://www.kancloud.cn/woshigrey/docker/935883
系统推荐
- Btrace入门
- 微博关注关系如何实现
- MongoDB高可用
- 如何安装Google BBR
- ShadowsockServer
- MAC CMS
- Paxos算法
- 多台centos服务器,文件互相备份
- JVM杂项
- PostgreSQL JSON类型字段常用操作
- 批量替换文件名中的指定字符串
- Linux dev shm目录
- 随机毒鸡汤:校服,是我和她唯一穿过的情侣装,毕业照是我和她唯一的合影。
