CAP 定理
C—— 数据一致性,A—— 服务可用性,P—— 服务对网络分区故障的容错性。
这三个特性在任何分布式系统中不能同时满足,最多同时满足两个。
Zookeeper
Zookeeper 保证的是 CP,即任何时刻对 Zookeeper 的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性,但是它不能保证每次服务请求的可用性。从实际情况来分析,在使用 Zookeeper 获取服务列表时,如果 zookeeper 正在选主,或者 Zookeeper 集群中半数以上机器不可用,那么将就无法获得数据了。所以说,Zookeeper 不能保证服务可用性。
Zureka
Eureka 遵守的就是 AP 原则。在它的实现中,节点之间是相互平等的,部分注册中心的节点挂掉也不会对集群造成影响,即使集群只剩一个节点存活,也可以正常提供发现服务。
Consul
Spring Cloud目前支持得最好的就是 Eureka,其次是 Consul,最后是 Zookeeper
Netflix 和 Spring Cloud的关系
netflix 是一家互联网流媒体播放商巨头,拥有巨大的访问量。使得其对微服务架构下的方方面面都有涉猎,孵化出众多项目,最后开源给社区。Spring Cloud对其进行进一步封装,形成现在的spring cloud netflix众多子项目
Eureka
- Eureka Server就相当于 zk
- Eureka Client可以分为两类:service provider / service consumer
- service consumer和service provider没有严格的界限,实际情况可能某个服务节点既是service consumer也是service provider.
三者的关系如下: 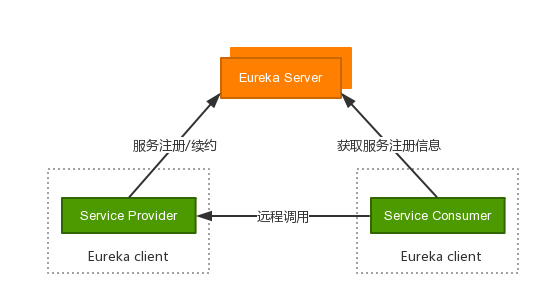
Eureka Server集群
可以运行多个Eureka Server实例来组建Eureka Server集群。不像zk那样,实例间会有master/slave之分,存在leader的选举,eureka server实例之间是互相平等的。
对某个eureka server的所有操作都会复制到该实例已知的其他eureka server实例之中。如果某个eureka server实例不可用,eureka client则会自动切换到另外一台eureka server实例进行相关操作。当eureka server实例恢复后,则又会重新对eureka client提供服务。
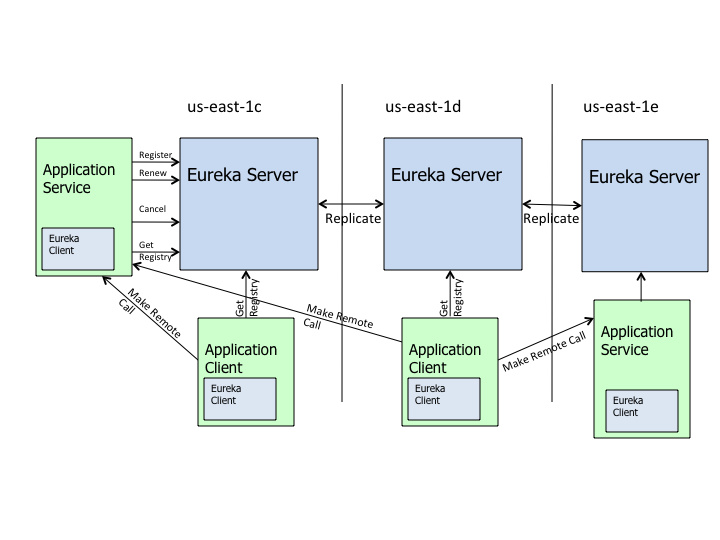
某个eureka server启动后,会首先尝试从已知的eureka server实例中获取注册表信息,完成初始化
eureka server和servcie provider直接会通过心跳机制定时更新注册表信息。如果一定时间内,eureka server没有收到service provider的心跳信息,则会将该service provider从注册表中移除。
如果某个eureka server实例在短时间内丢失了过多心跳信息,这个时候该实例将会进入**自我保护模式** ,在自我保护模式下,该eureka server实例不会再注销任何service provider节点。
自我保护模式
默认情况下如果某个 eureka server 实例每分钟收到的心跳信息低于一个阈值,并且持续15分钟,该eureka server则会进入自我保护模式。
自我保护模式下,该eureka server实例不会再注销任何service provider节点。
当eureka server实例收到的心跳数量恢复到阈值之上,则会退出自我保护模式。
自我保护模式的设计思想就是:宁愿保留错误的service provider信息也不盲目注销任何可能健康的service provider.
这样的设计思想就会导致service consumer可能拿到不可用的服务节点信息,因此要求service consumer要有容错机制,不如重试、断路器等。
eureka server的自我保护模式是可关闭的,通过eureka.server.enable-self-preservation = false来禁用
Service Provider
service provider在启动的时候,会向eureka server提供自己的ip、端口和服务列表等信息。 eureka server会维护一个注册表来保存这些信息,该注册表结构为一个嵌套的map,如下:
private final ConcurrentHashMap<String,Map<String,Lease<InstannceInfo>>> registry = new ConcurrentHashMap<String,Map<String,Lease<InstanceInfo>>>>();
当service provider实例的状态发生改变的时候,会向eureka server实例同步自己的服务信息,同时会执行replicateToPeers操作把信息同步给其他eureka server实例。
续约与注销
servcie provider启动后会定期向eureka server发送心跳信息已达到续约的目的。
如果某个eureka server实例在一定时间内没有收到service provider的心跳信息,则会把改service provider从注册表中注销剔除。
Service Consumer
service consumer在启动后会从eureka server中获取所有实例的注册信息并缓存在本地。这些缓存信息每隔30s更新一次。因此即便所有eureka实例都不可用,service consumer还是可以利用本地的缓存信息和service provider进行通信
由于service consumer获取的服务实例信息可能是不可用的,所以service consumer需要有容错机制,比如请求重试、断路器 。spring cloud都提供了对应的工具:
- ribbon:实现客户端的负载均衡
- hystrix:断路器
- feign:restful web service客户端,整合了ribbon和hystrix。
Ribbon
由以下几部分组成
ServerList:服务器列表,有不同的实现类
ServerListFilter:服务器列表过滤器,也有不同的实现类
IPing:服务实例探测器,有不同的实现类
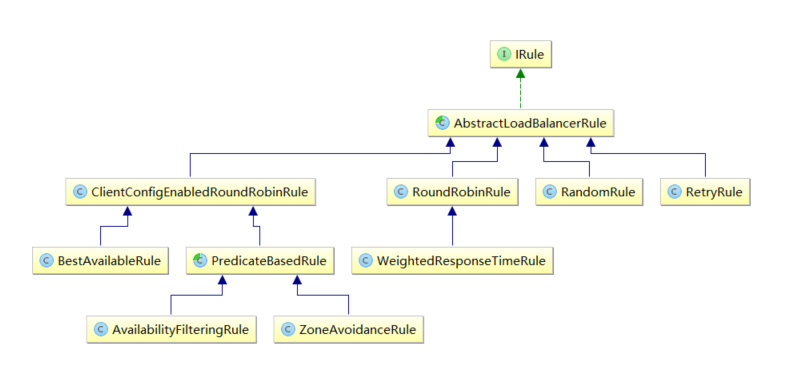
IRule:负载均衡策略,提供有 轮询、随机、响应时间加权等,类结构如下:
 5.RestClient:rest web service 请求工具
5.RestClient:rest web service 请求工具
Hystrix
雪崩效应
当某个基础服务不可用的时候,依赖于该服务的其他服务可能产生级联故障,进而导致整个服务故障的事件成为雪崩效应
在微服务中会有雪崩效应,在缓存集群中也可能发生雪崩效应
为了解决这个问题,则诞生了hystrix。
hystrix的设计思想
当连续调用某个服务N次都不响应的时候,hystrix则会启用,启用它会给服务器调用方返回一个符合预期的可处理的响应结果(fallback),而不是让调用方长时间等待或则抛出一个调用方无法处理的异常,从而避免级联影响整体服务导致雪崩。
注意: 1. 在失败率较低的情况下,hystrix并不会启用,因此hystrix还是会把故障返回给客户端。 2. hystrix启用后返回的fallback是可有开发者定制的。
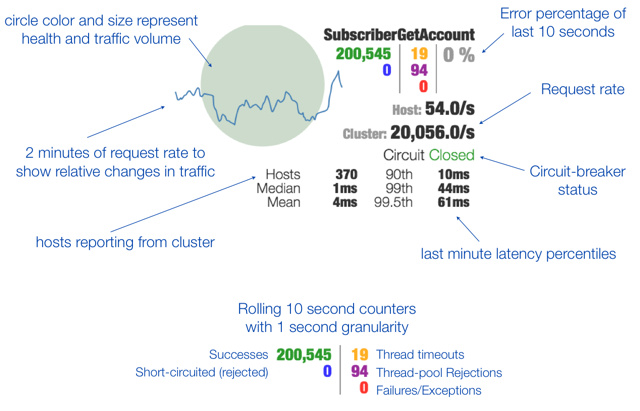
hystrix调用监控
hystrix会记录每分钟请求了多少次、多少失败、多少成功的等等信息,并且提供了可视化的工具hystrix dashboard对监控数据进行展示。图形化界面的含义如下:
Feign
feign整合了ribbon和hystrix,因此我们不需要再显式的使用这两个组件。
参考文献
系统推荐
- Cordova+Umi项目搭建步骤
- MySQL杂项
- CloudFlare 客户端证书的使用
- 弱引用示例
- JDK命令行工具
- 数组转树形结构只需两步
- 高可用通用方案
- Javassist整理
- gperftools
- Git Merge 、Rebase
- 分布式问题
- 免费 API 每日提供摸鱼日报,自动返回无水印图片,适用于公众号和小程序
- 随机毒鸡汤:不期待任何人,也不想被任何人期待。
